Idag i DN uttalar jag mig om varför personlighetstest ska användas i början av urvalsprocessen. Nedan kommer förtydligande och en hänvisning till forskningsstödet i varje uttalande.
Det är ganska svårt att mäta personlighet av en mängd olika orsaker. Resultatet är ganska osäkert. Störst effekt får man om man använder ett personlighetstest tidigt i processen, som ett screeningsförfarande, säger Anders Sjöberg, psykolog och forskare vid Stockholms universitet.
Med svårt menar jag här att det behövs väldigt många frågor i ett test för att få reliabilitet i måttet på personlighet. Reliabiliteten sätter gränsen för hur valid en mätning är, i rekryteringssammanhang sambandet mellan personlighet och arbetsprestation. Eftersom personlighetsmätningen sällan kommer över .30 i validitet har den mest verkan om man så tidigt som möjligt adminstrerar ett personlighetstest.
Om ett test ska bedömas hur effektivt det är är det tre begrepp som behöver uppskattas, baskvot (BK), urvalskvot (UK) och validitet (val). Baskvot anger andelen goda presterar som skulle lyckas om rekryteraren slumpade in kandidaterna. Urvalskvoten anger hur många kandidater det är som testas i förhållande till hur mångas som ska väljas ut. Och validiteten anger sambandet mellan i detta fall ett personlighetstest och arbetsprestation. Sambandet mellan urvalskvot, baskvot och ett urvalsförfarandes validitet generar tillsammans det som forskarna Taylor och Russell (1939) kallar framgångskvot. Med framgångskvot avses den andel kandidater som efter en viss anställningstid visar sig klara jobbet på ett tillfredsställande sätt (över genomsnittet). Denna kvot bör naturligtvis vara så hög som möjligt; det ideala är att 100 % av de nyanställda klarar jobbet på ett bra sätt, vilket skulle motsvara en framgångskvot på 1.00. Taylor och Russell räknade med hjälp av en statistisk teori ut sambandet mellan urvalskvot, baskvot och framgångskvot i kombination med olika validiteter i urvalsförfaranden. Med hjälp av den så kallade Taylor-Russell tabellen (Sjöberg, Sjöberg & Forssén, 2007) kan man avläsa under vilka kombinationer av urvalskvot och baskvot som olika nivåer på validiteten genererar högst framgångskvot. Generellt kan man säga
att ju högre validitet, desto högre framgångskvot, men vid extremt låg eller hög baskvot, eller hög urvalskvot har en ökning av validiteten – som resonemanget ovan visar – begränsad effekt.
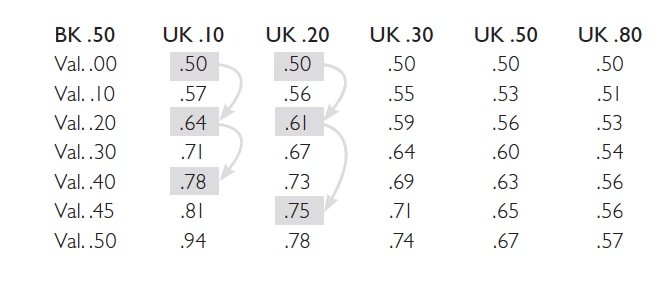
Om man tillämpar detta på ett exempel med 500 sökande till de 50 jobb som säljare, kan man räkna ut att urvalskvoten är 10 %, (50/500 = .10). Baskvoten är uppskattad till 50 % eller .50 (dvs om man slumpade in sökande skulle hälften överprestera. Om den urvalsmetod som används har en validitet på noll (validiteten kan variera mellan 0 och 1.00), kommer detta förfarande att generera en framgångskvot på 50%. I klarspråk innebär detta att hälften, 50 %, av de som anställs kommer att prestera bra, och att hälften inte kommer att bidra med en tillfredsställande arbetsprestation.
Det är dock sällan man låter slumpen styra vilka man anställer; oftast används någon form av systematisk urvalsmetod, som till exempel ett personligetstest som mäter målmedvetenhet. Validiteten i denna typ av test kan uppskattas ligga runt .20 (Sjöberg & Sjöberg, Näswall & Sverke, 2014) vilket enligt Taylor-Russell tabellen skulle generera en framgångskvot på 64 %. Således, genom att höja validiteten från 0 till .20 så identifierar man ytterligare en bra säljare till förmån för en mindre bra (.64 x 10). Använder man en urvalsmetod, tex ett begåvningstest med ännu högre validitet, kanske runt .40, får man en framgångskvot på 78% (se markering i tabellen). Inte så dumt för ett test som har en valditet på .40.
Validiteten är således viktig, men det gynnsamma förhållande har ett stort inflytande av den låga urvalskvoten. Om man istället höjer denna, vilket är fallet med tex second opinion, där urvalkvoten kanske är 50-100% istället för 10% så får vi inte samma nytta av validiteten. Istället för 78% rätt sjunker den till 63% rätt rekryteringar. Alltså ”störst effekt får man om man använder ett personlighetstest tidigt i processen, som ett screeningsförfarande”
Många använder testerna på fel ställen i rekryteringsprocessen, de används i slutet när de i stället borde användas i början. Om testerna används i början kan man göra bättre urval och få in personer som kanske annars diskrimineras.
Test är förhållandevis bra på att inte diskriminera eftersom det har visat sig att de inte mäter (beömer) diskrimineringsgrundade faktorer (kön, könsöverskridande identitet eller uttryck, etnisk tillhörighet, religion eller annan trosuppfattning, funktionsnedsättning, sexuell läggning och ålder). Test mäter istället personliga egenskaper som visat sig viktiga för att förutsäga arbetsprestation. Det betyder att om du använder test tidigt i processen kan jämställdheten gynnas. Att screena på CV och personlighetsbrev har visat sig öka diskrimineringen.
Jag rekommenderar aldrig att man ska använda testet som en second opinion i slutet av rekryteringen. Det kan kosta mellan 25.000 och 30.000 kronor per rekrytering, men det är bortkastade pengar om någon tolkar personlighetstesterna så sent i processen. Då är det bättre att slumpa. Slumpen diskriminerar åtminstone inte och det är bra mycket billigare jämfört med att testa, säger Anders Sjöberg.
Med samma argument som ovan avseende urvalskvoten är det bortkastad tid och pengar att införa ett test med så låg validitet som personlighetstest sist i processen. En metod som kostar mycket pengar bör ha en väldigt hög validitet för att göra nytta. Det har inte personlighetstest som mäter normalpersonlighet. Kan tänka mig att det att ett kognitvt test tillsammans med ett test som mäter avvikande tendenser (tex antisociala drag) kan ingå i en second opinion, men den låga urvalskvoten gör det ändå svårt att argumentera för ett sådan test när bara två kandidater återstår i urvalsprocessen. Med tanke på den sannolikt höga baskvoten så kan det vara bortkastat tid.
När det gäller slumpen så är den en underskattad metod vid urval. Då slumpen garanterat inte diskriminerar och den är väldigt billig att använda. All urvalsverksamhet handlar om att slå slumpen. I korrelationen mellan test och prestation (som kan variera mellan -1 och +1) anger vi hur långt från slumpen testet kan ta oss. Tyvärr finns det risk att vi sänker validiteten när vi använder testresultat som diskussionsunderlag inför ett urvalsbeslut (se nedan). Det är en stor risk att vi då tar in ovidkommande information som bidrar till diskriminering.
Han förklarar vidare: om två personer fått göra ett personlighetstest och den ena kandidaten har åtta poäng för en särskild egenskap och den andra personen har sju, innebär det inte att den som har åtta poäng nödvändigtvis är bättre. Det beror på att det finns en ganska hög felmarginal, vilket gör att den kandidaten som ligger lägre egentligen kan ha högst poäng.
Detta är reliabiliten i mätningen, dvs om varje kandidat skulle göra om testet så skulle resultatet variera. I personlighetstest finns det mätfel, dessa måste tas hänsyn till i tolkningen av 1 testpoäng. I ett test som kan variera mellan 0-10 är ofta felmarginalen 1-2 poäng, om du testar få personer sent i processen gör den höga baskvoten att det kommer vara liten skillnad mellan kandidaterna det finns då risk att små skillnader övertolkas.
Men om du gör personlighetstester på många personer i början av en process kommer du att få en del personer som har låga poäng och en del personer som har höga poäng inom en egenskap som till exempel emotionell stabilitet. Då kan du välja bort dem med extremt låga poäng, för de kommer sannolikt att få det jobbigt som chef, säger Anders Sjöberg.
Under gynnsamma förhållande, dvs låg urvalskvot kommer det finnas många testpoäng att välja på.
Om personlighetstester görs i slutet av en process ska rekryteraren inte titta på testresultatet förrän efter sista intervjun och väga samman de olika delarna var för sig, anser både Mattias Elg och Anders Sjöberg. Men det görs sällan, många använder personlighetstesterna som ett diskussionsunderlag.
– Då förstör man validiteten i testet, det blandas ihop med det som sägs under intervjun. Jag tror att 90 procent av testerna används fel. Men branschen har inga incitament att ändra sig eftersom man tjänar pengar på detta, säger Anders Sjöberg.
Det är inget fel att tjäna pengar på en god urvalsprocess. Men tyvärr så tolkas särskilt personlighetstest på ett felaktigt sätt.
Tolkning, eller sammanvägning, av testresultat (och all annan information som samlas in om kandidater i urvalssammanhang) kan ske på två väsensskilt olika sätt. Det vanligaste sättet att tolka testresultat på i praktiskt urvalsarbete är genom så kallad intuitiv tolkning (Viteles, 1925). Utgångspunkten för intuitiv tolkning är en kravprofil som definierar hur arbetsprestation manifesteras för det tilltänkta arbetet eller rollen. Denna typ av traditionella kravprofiler är oftast fastställda och uttryckta i kvalitativa termer, till exempel i beskrivningar av önskvärda egenskaper eller beteenden. Vid intuitiv tolkning ses testresultat i regel som en del av en helhet och det är personbedömaren (eller en grupp av personbedömare) som avgör om och på vilket sätt testresultat, och annan information, ska vägas in den sammantagna bedömningen. Det är också personbedömaren (eller gruppen) som genom en implicit mental process gör den faktiska sammanvägningen för varje kandidat och sätter denna i relation till kravprofilen. Processer som inrymmer intuitiv tolkning resulterar sällan i en explicit rangordning av kandidater. Intentionen är istället att de kandidater som genom ovanstående beskrivna process uppfattas passa eller ”matcha” kravprofilen bäst ska erbjudas anställning.
Det andra sättet att tolka eller sammanväga information på är genom så kallad mekanisk tolkning (Freyd, 1926). Detta förfaringsätt innebär:
- att det finns en i förväg fastställd specifikation för vad som ska tolkas – tidsperspektivet är centralt; specifikationen formuleras inte efter att informationen samlats in och den ska inte, utan explicit medvetenhet ändras efter hand.
- att specifikationen är explicit – alltså uttalad och dokumenterad så att intressenter kan ta del av den, och om så skulle ske; bevaka ändringar i specifikationen.
- att specifikationen beskriver logiken för tolkningen/samman-vägningen – det kan handla om en enkel summering av måtten man bestämt på förhand men det kan också vara avancerade algoritmer med ett stort antal komponenter baserade på evidens och där hänsyn tagits till i vilken utsträckning de olika informationsbitarna de facto överlappar i förhållande till kriteriet som ska prediceras.
- att tolkningen/sammanvägningen de facto görs mekaniskt – med till exempel en miniräknare eller motsvarande som garanterar konsistens över kandidater och som inte lämnar utrymme för subjektivitet eftersom det oundvikligen leder till att kandidaterna bedöms på olika premisser.
Vid mekanisk tolkning så är det alltså inte upp till den professionella personbedömaren att utifrån egen förmåga fastställa kravprofil (innehåll eller viktning), att väga ihop information (som till exempel testresultat och utfall från en intervju), matcha denna mot kravprofilen, eller att rangordna kandidater. Detta sker genom en standardiserad mekanisk process.
Redan på 1950-talet visade forskning att den mekaniska tolkningen är överlägsen den intuitiva när det gäller att förutsäga beteenden (Meehl, 1954), det vill säga att predicera exempelvis arbetsprestation. I en metaanalys fann Redan på 1950-talet visade forskning att den mekaniska tolkningen är överlägsen den intuitiva när det gäller att förutsäga beteenden (Meehl, 1954), det vill säga att predicera exempelvis arbetsprestation. I en metaanalys fann Grove, Zald, Lebow, Snitz & Nelson (2000) att av 136 studier, som ingick i analysen, så var 63 till den mekaniska tolkningens fördel, 8 studier visade att den intuitiva tolkningen var överlägsen, och 65 studier visade att metoderna leder till likvärdiga nivåer vad gäller prediktiv validitet.
Och det är just i skillnaden mellan det intuitiva och mekaniska förhållningssättet, inte i hur man viktar de olika informationsbitarna, som visat sig påverka validiteten allra mest (Sawyer, 1966; Grove etal., 2000). Det innebär att jakten på de perfekta vikterna, eller att förkasta mekanisk tolkning med hänvisning till att vikterna inte nått perfektion, saknar logisk grund. Forskning visar tydligt att givet samma information så leder mekanisk tolkning till högre prediktion jämfört med intuitiv tolkning (Kuncel, Klieger, Connelly & Ones, 2013).
Den mekaniska tolkningen har, förutom en överlägsen prediktiv validitet, en betydligt större kostnadseffektivitet jämfört med den intuitiva tolkningen (Highhouse, 2008). När en ekvationen väl är på plats så är kostnaden per kandidat avsevärt lägre jämfört med den intuitiva tolkningen där informationen för varje enskild kandidat så att säga tolkas separat.
Replikerbarheten och transparensen i den mekaniska tolkningen möjliggör dessutom systematisk utvärdering och därmed kontinuerligt arbete med förbättringar. Exempelvis kan viktningar förfinas och bli mer reliabla och valida i takt med att det empiriska underlaget ökar. Motsvarande är inte möjligt med den intuitiva tolkningen eftersom subjektiviteten hos bedömaren ständigt ändrar viktningen utan att ta hänsyn till kriteriet. Replikerbarheten och transparensen garanterar att kandidater jämförs på samma sätt utifrån samma premisser; att hänsyn tas till relevant information och inte minst att irrelevant information utesluts från tolkningen.
Replikerbarheten och transparensen möjliggör också spårbarhet. Inte minst i praktiska urvalssituationer är det lämpligt att kunna besvara frågan om varför en kandidat erbjuds tjänsten och inte en annan. Att logiskt kunna härleda processen som lett fram till beslutet och därmed på begäran kunna bevisa hur processen fram till beslutet gått till är en annan följd av spårbarheten.
Ovanstående kan tyckas vara självklarheter och är kanske även den intentionella essensen i intuitiv tolkning men faktum är att den intuitiva tolkningen har svårt att göra anspråk på dessa punkter. Med sitt ostandardiserade format ger den intuitiva tolkningen utrymme och möjlighet till att relevant information inte vägs in, att irrelevant information vägs in, att viktningen sker på ett mindre korrekt sätt, och den medför oundvikligen att bedömningsgrunderna varierar mellan kandidater. I praktiken leder det till medveten eller omedveten särbehandling av olika slag vilket ökar risken för diskriminering.
Trots den mekaniska tolkningens överlägsenhet så är den sällan implementerad fullt ut i praktiskt urvalsarbete; intuitiv tolkning utgör standardförfarandet inom praktiskt urvalsarbete idag även om intresset och efterfrågan för standardiserade och evidensbaserade lösningar så som mekaniska tolkningsmodeller har ökat på senare år.
Referenser
Mount, M. K., & Judge, T. A. (2001). Personality and job performance at the beginning of the new millennium: What do we know and where do we go next? International Journal of Selection and Assessment, 9, 9–30.
Barrick, M. R., & Mount, M. K. (2005). Yes, personality matters: Moving on to more important matters. Human Performance, 18, 359–372.
Borman, W. C., & Motowidlo, S. J. (1993). Expanding the criterion domain to include elements of contextual performance. In N. Schmitt, & W. C. Borman (Eds.), Personnel selection in organizations (pp. 71–98). San Francisco, CA: Jossey-Bass.
Freyd, M. (1926). The statistical viewpoint in vocational selection. Journal
of Applied Psychology, 4, 349–356.
Gonzalez-Mulé, E., Mount, M. K., & Oh, I.-S. (2014, August 18). A meta-analysis of the relationship between general mental ability and nontask performance. Journal of Applied Psychology. Advance online publication. http://dx.doi.org/10.1037/a0037547
Grove, W. M., Zald, D. H., Lebow, B. S., Snitz, B. E., & Nelson, C. (2000). Clinical versus mechanical prediction: A meta-analysis. Psychological Assessment, 1, 19–30.
Highhouse, S. (2008). Stubborn reliance on intuition and subjectivity in employee selection. Industrial and Organizational Psychology, 1, 333–342.
Hunter, J. E., Schmidt, F. L., & Le, H (2006). Implications of direct and indirect range restriction for meta-analysis methods and findings. Journal of Applied Psychology, Vol. 91, No. 3, 594–612.
Hurtz, G. M., & Donovan, J. J. (2000). Personality and job performance: The Big Five revisited. Journal of Applied Psychology, 85, 869–879.
Kuncel, N. R., Klieger, D. M., Connelly, B. S., & Ones, D. S. (2013). Mechanical versus clinical data combination in selection and admissions decisions: A meta-analysis. Journal of Applied Psychology, 98, 1060–1072.
Le, H., & Schmidt, F. L., (2006). Correcting for Indirect range restriction in meta-analysis: testing a new meta-analytic procedure. Psychological Methods, 11, 416–438.
Meehl, P. E. (1954). Clinical versus statistical prediction. Minneapolis, MN: University of Minnesota.
Mount, M. K., & Barrick, M. R. (1995). The Big Five personality dimensions: Implications for research and practice in human resources management. Research in Personnel and Human Resources Management, 13, 153–200.
Rotundo, M., & Sackett, P. R. (2002). The relative importance of task, citizenship, and counterproductive performance to global ratings of job performance: A policy-capturing approach. Journal of Applied Psychology, 87, 66–80.
Sackett, P. R., & DeVore, C. J. (2001). Counterproductive behaviours at work. In N. Anderson, D. S. Ones, H. K. Sinangil, & V. Viswesvaran (Eds.), International Handbook of Work Psychology (Vol. 1, pp. 145–164). London, UK: Sage Publications.
Salgado, J. F. (1997). The five-factor model of personality and job performance in the European Community. Journal of Applied Psychology, 82, 30–43.
Salgado, J. F. (2003). Predicting job performance using FFM and non-FFM personality measures. Journal of Occupational and Organizational Psychological, 76, 323–346.
Sawyer, J. (1966). Measurement and prediction, clinical and statistical. Psychological Bulletin, 66, 178–200.
Schmidt, F. L., & Hunter, J. E. (1998). The validity and utility of selection methods in personnel psychology: Practical and theoretical implications of 85 years of research findings. Psychological Bulletin, 124, 262–274.
Sjöberg, S., Sjöberg, A., Näswall, K., Sverke, M. (2012). Using individual differences to predict job performance: Correcting for direct and indirect restriction of range. Scandinavian Journal of Psychology, DOI: 10.1111/j.1467-9450.2012.00956.x
Sjöberg, A., Sjöberg, S., & Forssén, K. (2006). Predicting Job Performance. Manual. Stockholm: Assessio International.
Taylor, H. C., & Russell, J. T. (1939). The relationship of validity coefficients to the practical effectiveness of tests in selection. Journal of Applied Psychology, 23, 565–578.
Viswesvaran, C., Schmidt, F. L., & Ones, D. S. (2005). Is there a general factor in ratings of job performance? A meta-analytic framework for disentangling substantive and error influences. Journal of Applied Psychology, 90, 108–131.
Viswesvaran, C., & Ones, D. S. (2000). Perspectives on models of job performance. International Journal of Selection and Assessment, 8, 216–226.
Viteles, M. S. (1925). The clinical viewpoint in vocational selection. Journal of Applied Psychology, 9, 131–138.