
Andra dagen på SIOP i Washington inleddes med en diskussion om ”job performance”. Den som avslutade diskussionen var självaste Campbell, J.P., känd forskare som ägnat hela sitt liv åt att validera bedömningstjänster i arbetslivet. Han påminde att arbetsprestation är individuella differenser (prestationer) som individen själv kan påverka. Han var därför kritisk mot begreppen team performance, organization performance. Utgångspunkten enligt Campbell alla prestationsmodeller bör vara individens prestation. För övrigt bjöd seminariet på två nya modeller som jag ska kolla närmare på när jag får tillgång till papers, den ena handlade om fysisk prestation som ofta behandlats i studier och modeller på ett övergripande sätt. De nya modellerna bryter istället ned den fysiska prestationen i mindre komponenter. Detta kan i sin tur innebära att de fysiska test som genomförs inom tex försvarsmakten kan förbättras i framtiden. Den andra nya modellen som föreslogs har tagit utgångspunkt i Campbells ursprungliga prestationsmodell och Dave Bartrams Big Eight model. Utgångspunkten i deras utveckling var, precis det som vi använder i Assessment Engine, tre breda prestationsdimensioner, task performance, organizational citizenship behavior och counterproductive work behavior. Sedan bryter modellen ned dessa beteende i mindre komponenter.
Nästa seminarium handlade om kandidatens upplevelse av rekryteringsprocessen som fått enormt genomslag senaste åren. I den paneldebatt jag var på kan man konstatera att detta är ett högts diffust begrepp, samtidigt som det är ytterst viktigt för organisationer. Det ramlar ned till att organisationer vill attrahera rätt kandidater, och även om kandidaterna inte får jobbet vill de inte att de pratar ”skit” om organisationen. Inom forskningen, sedan 1939, kallas det att höja baskvoten, dvs att få bra sökande till tjänsten. Jag blev inte klokare av denna paneldiskussion än vad jag redan vet, nämligen att organisationer tvekar att använda valida metoder för att de är rädda att skrämma bort kandidater. Men ingen kan presentera data på att vissa metoder skrämmer bort kandidater, så vad är problemet?
På eftermiddagen ägnade jag min tid att gå runt på utställningen där både assessment leverantörer och bokförlag visar sina produkter. En reflektion är att stora företag som IBM är med (det lite komiska var att de hade teknikproblem och kunde inte starta sina datorer!). När jag frågade en av utställare från IBM, efter de fått igång sina datorer, vad de menar med AI och hur det går till fick jag massa buzzwords som att ”vi matchar sökande till jobb med AI och machine learning”?????
Behållningen denna dag var istället en kille jag träffade (Garett N Howardson) som hade utvecklat en ny analysmetod för att kunna analysera beteende i väldigt små grupper, samtidigt som analysformen går att presentera på ett begripligt sätt till praktiker som kanske inte är intresserad av statistik. Allt helt gratis om du använder R.
Jag tittade sedan in på ett seminarium som behandlade AI. Några frågor som togs upp av panelen var dessa.
- Hur kan AI användas i vanlig testning?
- Hur reagerar kandidater att AI används för att analysera?
- Hur ska algoritmer utvecklas?
- Kommer AI ersätta IO psychologist?
- Är det lagligt att använda Facebook i urval?
Det blev en intressant diskussion, men återigen är det svårt att diskutera AI utan en gemensam definition. Inget nytt för mig denna gång.
På lördagen började jag dagen med en session om personlighetsbedömning som INTE är självrapporterade mätningar (traditional testing), sk icke-traditionell testning. Som exempel på icke-traditionell testning togs exemplet upp där forskare tagit data från facebook och kollat sambandet mellan Likes på facebook och din personlighet. Jag har inte varit imponerad av resultatet då korrelationerna ofta bara uppnår .30 -.40 mellan ”LIKES” och personlighets-testpoäng. Att säga att man då kan mäta personlighet med AI liknande metoder (som egentligen är text mining) är att överskatta resultatet, tycker jag. Detta hade professor Harms undersökt betydlig mer djuplodande än jag. Och ha kom fram till dessa slutsater.
- Personer utan bakgrund inom psykologisk forskning har varit inblandade i de inledande analyserna (läs Cambridge Analytica).
- I stort sätt alla studier har använt personlighetstest där validiteten är tveksam
- När man kollar noga i resultatet så upptäcker man konstiga resultat för Big Data metoden, tex att öppenhet och extraversion har ett negativt samband. Big Data analyserna visar också på en dålig diskriminering mellan de fem faktorerna, dvs det finns en hög korrelation mellan faktorerna (medel r = .37)
- Och varför har ingen undersökt facetterna under Big Five? Onekligen går det att göra. Harms Misstänker att forskarna mörkat detta då resultatet skulle bli än mer tveksamt.
Sammantaget visar resultatet på oklara samband avseende Big Data analysernas förmåga att ersätta personlighetstestningen.
Nästa presentatör, Piers Steel från University of Calgary presenterade en mycket intressant studie där han jämförde hur mycket Big Five kan förklara av variationen i arbetstillfredställelse, karriär tillfredsställelse och livstillfredställelse i jämförelse med om vi analyserar facetterna under Big Five, sammanlagt 30 facetter. Resultatet visar att med facetterna kan förklara lite mer än Big Five i tillfredställelse, men över 100% mer förklarad varians mer i tillfredställelse med arbetskarriären och i livet i stort. Detta går emot gängse mot hypotesen att Big Five ska användas när breda kriterier ska förutsägas. I Piers analyser finns stöd för att det är facetterna under Big Five som är den drivande kraften för att predicera senare känslor och beteenden. Detta stämmer också överens med professor Oswalds resonemang (redan förra året på SIOP) att i framtiden kan vi öka validiteten för personlighet genom att kolla på alla nivåer samtidigt, generell personlighet (1 faktor), Getting along and Getting Ahead (2 faktorer), Big Five, 30 facetter och till och med gå ned på itemnivå (frågenivå). Mycket spännande, eller hur.
Ett trevligt återseende blev det med Jeff Foster som i många år har jobbat för Hogans, nu har han startat eget (https://passkeysint.com) och presenterade sin egen research där han kunde visa att det går att öka validiteten i personlighetsbedömningar om man också tar hänsyn till hur andra bedömer personens personlighet. Jeff var med på två seminarier som jag följde med på. Det andra handlade om att det går att få ut unik information av att bara ställa en fråga, om tex personlighet, sk short scales. Intressant då detta alltid har varit ett BIG NO, dvs att bara ställa en eller några fåtal frågor för att bedöma personlighet.
Detta tog vi delvis utgångspunkt vid utvecklingen av personality30. När vi utvecklade personlighetstestet som finns i Assessment Engine landade vi i 150 item som kan delas upp i 30 facetter som kan sammanfattas i Big Five. När vi var klara med detta tog vi ut 30 item med hjälp av Item Response Theory och en teoretisk tolkning att 1 item kan spegla 1 facett. I vårt korta test (personality30) har vi låg reliabilitet i varje Big Five faktor (mätt med cronbach alpha). Men vad som händer, som kan verka väldigt kontraintuitivt, är att validiteten ökar. Nedan ser ni validiteten (korrelationen, r) mellan tre av Big Five faktorerna (N, E och C) bedömt med 150 item i jämförelse med 30 item. Reliabiliteten är låg i personality30 (runt .64) men vad ni ser i tabellen ser är att N (känslomässig instabilitet) har en lika hög negativ korrelation med lön för både den långa versionen och den korta versionen av testet. Och för E (Extraversion) och C (Målmedvetenhet) har den långa versionen inget signifikant samband med lön, till skillnad från den korta versionen av samma test.
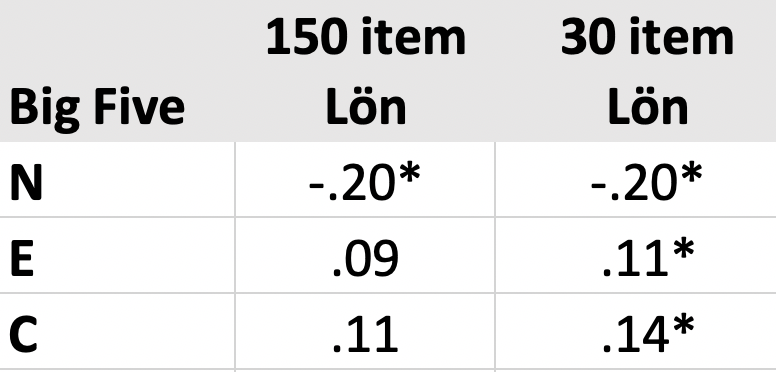
Detta betyder att det är fullt tillräckligt med 30 item för att på ett väsentligt sätt rangordna individer för i detta fall predicera vilken lön de har (samma sak visade sig för flera arbetsrelaterade variabler, om ni vill se våra psykometriska analyser maila mig på info@psychometrics.se. Vi har naturligtvis sammanfattat psykometrin i en manual).
Innan jag tog taxin till flygplatsen var jag naturligtvis tvungen att titta på SIOP:s höjdpunkt, dvs den första presentationen av den nya metanalysen av sambandet mellan begåvning och prestation i arbetslivet. Det är Jack Kostar och Deniz Ones som granskat 25 tidsskrifter,k sammanlagt har de hittat 178 olika test, de har haft tillgång till 59 test manualer och sammanlagt hittat 14 516 studier med sammanlagt 747 976 individer. Faktum är att denna uppdatering är den första sedan 70-80 talet, även om Hunter & Schmidts sammanfattning kom 1998 så var det data från en svunnen tid som utgjorde den stora delen av datan som låg till grund för estimatet .51.
Och vad blev då resultatet, det tänker jag inte säga nu. Det kommer jag säga när artikeln är publicerad, men jag kan säga att mycket tyder på att jag ska revidera algoritmerna i Assessment Engine snart, inte minst pga att att verbala test är en nödvändighet att ha med i bedömningen, det räcker inte med ett matristest för att förutsäga prestation i arbetslivet, vilket jag sagt i många år.
Sammantaget en mycket bra SIOP konferens, 50% av det man hinner med handlar om att falsifiera sina egna nollhypoteser, dvs gå på de seminarier man egentligen inte tror på. Tyvärr är det fortfarande mycket marknadsföring hos företag på SIOP som har lite med den seriösa forskningen att göra, vilket jag tycker är synd. Tråkigt när stora företag står och säger sig ha löst många problem inom tex urval medan forskarna tycker tvärtom i ett angränsande rum, detta borgar inte för att minska gapet mellan forskning och praktik. Min sammanfattande trendspaning är följande.
- AI, Big Data, påväg ned i intresse
- EQ helt borta på kartan
- Personlighet, särskilt ett intresse för den mörka sidan
- Lite mer om begåvning, med särskild betoning på andra faktorer än generell intelligens
- Psykometrisk forskning sker nu i R, ingen analyserar med SPSS längre.
Och Washington är trevligt, och roligt att vi var en hel del nordbor på plats, träffade flera norska kollegor och många från Sverige.
Nästa år är det bara att borsta av cowboyhatten, då är SIOP i Texas.
