PERSONLIGHET är stabila mönster i att tänka, känna och handla på ett konsekvent och karaktäristiskt sätt i olika situationer och över tid. Dessa mönster har betydelse för oss människor på en mängd olika sätt. Betyg har betydelse då det kan avgöra vilken utbildning som personen kan välja, och det i sin tur kan påverka vilket yrke man sedan väljer. Nedan sammanfattar jag vad vi vet om betyg, personlighet och akademisk framgång.
Personlighetens Fem Faktor Modell (FFM) kallas ofta kort och gott, Big Five. Både de svenska och engelska benämningarna på dessa fem faktorer varierar, men de mest allmänt vedertagna är:
MÅLMEDVETENHET – conscientiousness – ordningsamhet, disciplin och prestationssträvan
SYMPATISKHET – agreeableness – tillit, värme och samarbetsvilja
KÄNSLOMÄSSIG INSTABILITET – emotional instability – stresskänslighet, vaksamhet och beredskap
ÖPPENHET – openness – intellektuell nyfikenhet, fantasi och öppenhet för nya idéer
EXTRAVERSION – extraversion – utåtriktning, energi och spänningssökande
Alla individer kan bedömas från låg till hög nivå när det gäller dessa personlighetsdrag, men det är den centrala tendensen som är individens sk ”traitnivå”. Det innebär till exempel att den mer introverta individen kan, med viss ansträngning, bete sig extravert. Individen föredrar det dock inte, och det faller sig inte heller naturligt. En individ kan alltså utföra beteenden längs hela skalan, men det är den centrala tendensen som utgör individens utgångspunkt för tankar, känslor och beteenden.
Vilka centrala tendenser är det då som kan påverka vilket betyg eleven får? Innan vi går in på det är det viktigt att komma ihåg att personlighet utgör typiska drag, till skillnad från intelligens som utgör maximal prestation. Intelligensen, som jag skrivit om i tidigare inlägg, hjälper oss att hela tiden ”pusha gränsen” med att klara så mycket som möjligt i skolan, medan personligheten styr oss långsiktigt att känna och tänka på ett sätt som kan gynna våra betyg.
Forskarna McAbee och Oswald publicerade redan 2013 en meta analys om sambanden mellan Big Five och betyg och fann att Målmedvetenhet – conscientiousness – ordningsamhet, disciplin och prestationssträvan hade ett positivt samband med betyg i grunsdkolan (r=.26).
När forskaren Sakhavat Mammadov uppdaterade meta analysen genom att bredda kriteriet till akademisk framgång genom att förutom betyg även ta med provresultat, examinationsresultat och standardprov (motsvarande nationella prov) upprepades resultat till nästa exakt samma samband (r=.27). I denna analys visade sig att sambandet var nästan lika högt genom hela skolgången från grundskola till universitetet/högskola.
Extraversion fann samma forskare ha ett svagt positivt samband i grundskolan (r=.15), men detta samband är noll i senare skolgång. Detsamma gäller för sympatiskhet bedömd i grundskolan (r=.18) där sjunker sambandet sedan sjunker betydligt när eleverna kommer upp i högre stadier (r=.08).
Känslomässig instabilitet hade ett nollsamband med akademiska framgång genom alla stadier i skolan. Lite ångest och oro är inga större problem för betyget, vad det verkar.
Öppenhet visar ett positivt samband med framgång i skolan. Övergripande sambandet var dock lågt (r=.16) men när vi delar upp det i grundskola, gymnasium och eftergymnasiala kurser ser vi att stadie i skola är en stark moderator, där sambandet är riktigt högt i grundskola (r=.40) för att sedan avta i gymnasium (r=.22) för att sedan nästa helt försvinna i högre utbildning (r=.10). Öppenhet är enligt mig den svåraste faktorn att mäta. Så en förklaring kan vara att mätningen av öppenhet fokuserar ibland att mäta självrapporterad intelligens, dvs frågorna som ingår i mätningen är när knutna till att vara bra i skolan, att gilla att lösa problem etc så detta resultat tycker jag ska tolkas med försiktighet.
Att målmedvetenhet har ett positivt samband med prestation i skolan är inte konstigt då denna breda faktor består av två aspekter som är nära knutna till prestation i skolan, nämligen strävsamhet och ordningsamhet. Aspekten strävsamhet avser tendensen att arbeta hårt och målmedvetet mot långsiktiga mål. Att ha riktning, ambition och drivkraft och att vara benägen att kunna stå emot distraktioner och bibehålla fokus ingår också i denna aspekt.
Aspekten ordningsamhet handlar om att vara ordentlig, systematisk och punktlig. Att noggrant följa regler samt moraliska och etiska riktlinjer och principer är också en viktig del, delar som kan vara avgörande för prestation i skolan.
Att öppenhet har ett positivt samband med prestation i skolan är inte heller konstigt då då den ena aspekten av öppenhet representerar en öppenhet för att söka sig till och ta in nya intryck och upplevelser samt uppskatta och stimuleras av sinnesintryck.
Den andra aspekten av öppenhet benämns ofta intellekt. Där ryms tendensen att tycka om intellektuella utmaningar, som abstrakta resonemang, teoretiska diskussioner och problemlösning. Att vara frågande, forskande, nyfiken och villig att lägga ner tid och ansträngning på intellektuella och kognitivt utmanande aktiviteter ingår i denna aspekt. Förmodligen är det den aspekten som driver det positiva sambandet mellan öppenhet och framgång i skolan, enligt resultatet mest betydande i lägre åldrar.
Kommentar
Tillsammans med intelligens verkar målmedvetenhet var de psykologiska individuella egenskaperna som tillsammans kan förklara en del av variationen i betyg och hur man lyckas i skolan. Viktigt att komma ihåg att det är mycket variation som inte förklaras av dessa egenskaper där lärandemiljön, lärarnas prestation, intresse motivation, andra studenters beteenden kan vara avgörande hur det går i skolan. Personlighet är en liten pusselbit.
Referenser
McAbee, S. T., & Oswald, F. L. (2013). The criterion-related validity of personality measures for predicting GPA: A meta-analytic validity competition. Psychological Assessment, 25(2), 532–544.
Mammadov, S. (2022). The Big Five Personality Traits and Academic Performance: A Meta-Analysis. Journal of personality, 90, 222-225.
I en nyligen publicerad meta analys uppskattas sambandet mellan intelligens och skolbetyg till .54. Förklaringen kan vara att hög intelligens betyder att personen ifråga har lättare för logisk problemlösning i jämförelse med dem som ligger på lägre nivåer i denna förmåga, och det i sin tur kan påverka nivån på skolbetyg.
Vi intelligenstestar i Sverige när vi administrerar Högskoleprovet en gång om året till ca 70 000 personer som vill in på högre utbildning. Vi kallar det INTE intelligenstest eftersom det är ett politiskt känsligt begrepp i Sverige, men inte desto mindre finns det positiva samband mellan ett vanligt intelligenstest och högskoleprovet. Det test polisen använder idag (unIQ) kan betraktas som ett vanligt intelligenstest, detta test och Högskoleprovet har ett högt samband med varandra (.63). Att skillnaden inte är ännu högre beror på Högskoleprovets uppbyggnad med testinnehåll glider mer åt kristalliserad intelligens (verbal numerisk) och UnIQ som är uppbygd mer åt det icke numeriska-verbala hållet, sk flytande intelligens.
Fakta
Cattell (1963) distinguished between fluid intelligence (Gf) — (broad ability to reason, form concepts, and solve problems using unfamiliar information or novel procedures and crystallised intelligence (Gc) — (the ability to reason using previously learned knowledge or procedures).
Detsamma gäller för det sk Inskrivningsprovet för värnpliktiga, även det ett intelligenstest. Gustafsson och Carlstedt (2005) har visat att innehållet i Inskrivningsprovet och högskoleprovet skiljer sig ifrån varandra, där Inskrivningsprovet lutar sig mer mot flytande intelligens och högskoleprovet innehåller mer av kristalliserad intelligens.
I meta analysen publicerad 2015 uppskattas det övergripande sambandet, baserat på 240 studier och en undersökningsgrupp på 105 185 personer till .54. Där de mixade testen, både kristalliserad och flytande intelligens kommer upp i ett ännu högre samband (.60).
Detta resultat går att generalisera till svenska förhållande, åtminstone till tiden runt 2014 då Magnus och Christina Wikström i Umeå fann ett samband mellan högskoleprovet och betyg runt .45.
Stefan Annell, Magnus Sverke och jag visade även i en studie att när man summerar ett språktest, Högskoleprovet och unIQ var sambandet mellan de tre testen och betyg på polishögskolan .43. Med andra ord hur man presterade på testen kunde förutsäga hur bra polis man bedömdes vara under utbildningen. När jag räknar om detta samband genom att tillämpa samma metod som meta analysen blir korrelationen exakt densamma som i meta analysen .54.
Men, viktigt att komma ihåg att samband inte säger något om orsak och verkan. Utbildning kan påverka hur bra man är på att klara ett intelligenstest. En meta analys från 2018 (Ritchie etl al, 2018) visar att studietid kan påverka resultatet på ett intelligenstest avsevärt. Sannolikt finns det ett samband åt båda hållen, men det spelar mindre roll i urval, där är vi endast intresserade av att förutsäga framgång i kommande studier baserat på ett resultat som kan bedömas innan utbildningen.
Slutsats
Högskoleprovet, unIQ, språktest, inskrivningsprovet är alla exempel på test som ska mäta den maximala kognitiva förmågan hos en individ, dvs intelligens. Uppbyggnaden av testet kan variera i form av olika typer av uppgifter, men de allra flesta testen har ett positivt samband med skolbetyg, både i Sverige och i andra länder. Det betyder att poäng på ett intelligenstest kan förutsäga skolbetyg, inte perfekt men hyfsat bra.
Jag återkommer med flera individuella faktorer som kan förutsäga skolbetyg.
Referenser
Annell, S., Sjöberg, A., Sverke, M. (2014). Use and Interpretation of Test Scores from Limited Cognitive Test Batteries: How g + Gc Can Equal g. Scandinavian Journal of Psychology, 55(5), 399–408.
Carlstedt, B., & Gustafsson, J. E. (2005). Construct validation ofthe Swedish Scholastic Aptitude Test by means of the Swedish Enlistment Battery. Scandinavian Journal of Psychology, 46(1).
Cattell, R. B. (1963). Theory of fluid and crystallized intelligence: A critical experiment. Journal of Educational Psychology, 54, 1–22.
Roth, B., et al (2015). Intelligence and school grades: A meta-analysis. Intelligence 53,118–137
Ritchie, S. J., & Tucker-Drob, E. M. (2018). How Much Does Education Improve Intelligence? A Meta-Analysis. Psychological Science, 29(8), 1358–1369.
Wikström, M., & Wikström, C. (2014). Who benefits from university admissions tests? – A comparison between grades and test scores as selection instruments to higher education. Umeå Economic Studies 874, Umeå University, Department of Economics.
En vanlig fråga jag får från studenter och praktiker är; kan betyg i skola förutsäga prestation i senare arbetsliv? Jag har länge varit osäker på detta, och ibland missar även jag forskning på detta område. När jag sökte på annat träffade jag på en meta analys från 1996, en meta analys där sk primär data samlats in för länge sedan, men resultatet kan ändock kasta lite ljus på frågan om betygets värde för rekryterare.
I meta analysen från 90-talet finner forskarna att sambandet mellan betyg och arbetsprestation ligger runt .30. I sammanhanget kan detta ha betydelse för urvalsbeslutet om man jämför med andra saker vi kan bedöma i en rekryteringsprocess. Men, det finns stora skillnader mellan om vi pratar betyg från gymnasiet (college) eller universitetet (masterutbildning). Sambandet är betydligt högre för universitetsutbildningen (.46) i jämförelse med gymnasiet (.33). Det är även en skillnad om vi bedömer arbetsprestation efter 1 år (.45), 2-5 år (.30), och 6 år eller senare har sambandet sjunkit betydligt (.11). De riktigt gamla studierna (innan 1960) visade på betydligt högre validitet (.45). Nämnas bör att prestation bedömdes i ca 80% i studierna av närmaste chefen och i resterande fall av en medarbetare eller lärare som ansågs som experter inom området (tex en medicinsk expert som bedömer läkares prestation).
Praktiska konsekvenser
Det är inte konstigt att betyg förutsäger arbetsprestation, särskilt om utbildningen är nära knuten till arbetet. Utbildning handlar om lärande, och de som har högst lärandekvalitet har sannolikt chansen klara jobbet bättre än andra som har lägre betyg på utbildningen.
Men jag rekommenderar inte per automatik använda dagens svenska betyg för urvalsbeslut. Anledningen är att vi saknar studier på om våra betyg är säkra (reliabla), mycket tyder på att dagens betygssystem har allvarliga brister (det är en annan historia som jag får anledning att återkomma till).
Meta analysen är även relativt gammal och all data är insamlad i Nordamerika, där de dels har en annan skolgång, men också ett annat betygssystem. Därför är det svårt att generalisera resultatet till Sverige idag. En kvalificerad gissning är att lärande i skolan påverkar arbetsprestationen, men betygen vi ser (den observerade bedömningen av lärande) har tyvärr högst tveksam kvalitet för att ingå i en seriös personbedömning.
Referens
Roth, P. L., BeVier, C. A., Switzer, F. S. III, & Schippmann, J. S. (1996). Meta-analyzing the relationship between grades and job performance. Journal of Applied Psychology, 81(5), 548–556. https://doi.org/10.1037/0021-9010.81.5.548
I vår bok Personlighet i arbete har vi ett kapitel om extrema personlighetsdrag i arbete. Där tar vi upp olika modeller för att förklara hur den mörka sidan av personligheten kan vara både en fördel och en nackdel för individen och organisationen. Nu har det kommit nya forskningsresultat som tar upp det gemensamma med Fem Faktor Modellens A skala, Agreeableness eller Sympatiskhet, som vi valt att kalla det på svenska och den mörka sidan av personlighet. Först är det viktigt att tydliggöra vad som avses med extrema personlighetsdrag. Eftersom personlighetsdrag är ungefärligt normalfördelade i populationen, betyder det att de allra flesta, närmare 70 procent, har genomsnittliga nivåer. Inkluderar man dem som har ytterligare något över respektive under genomsnittet av ett personlighetsdrag omfattar det totalt omkring 95 procent av populationen. Det betyder att det är en mycket liten andel personer (ungefär 2,5 procent vardera) som har så pass låg respektive hög nivå av ett personlighetsdrag att de kan kallas extrema. Detta resonemang syftar på skillnader mellan individer inom ett personlighetsdrag. Sympatiskhet som består av följande facetter (se bild nedan).
En viktig frågeställning, inte minst inom arbetslivet, är förstås om det är bra eller dåligt med extrema nivåer av personlighetsdrag. Som med många andra frågor är det svårt att ge ett enkelt svar. Först och främst kan en allmän beskrivning av en person nivå av Sympatiskhet, där varje facett betraktas var för sig, innehålla egenskaper som kan uppfattas som både bra och dåliga. Extrema nivåer (höga och låga) på flera av sympatiskhets facetter kan beskrivas i såväl positiva som mer negativa termer. Om en extrem nivå ska kunna sägas vara bra eller dålig, eller snarare vara en tillgång, en belastning eller en behöver man sätta egenskapen i relation till något ett kriterium, inom arbetslivet handlar det om vad man gör på jobbet. Det vill säga svara på frågan: Är det bra eller dåligt för vad som ska göras och när? En individ skulle till exempel kunna beskrivas som avsaknad av medkänsla (A6) men prestera mycket bra i en roll som ställer krav på att man kan ta tuffa beslut och bana väg för andra.
När dysfunktionalitet och problematiska beteenden är i fokus använder man ofta termer som ”personlighetens mörka sida” för att beskriva dessa egenskaper. Forskningen om kopplingen mellan personlighet och dysfunktionella beteenden har delvis pågått parallellt med forskningen om FFM.
Forskningen om den mörka sidan föreslår flera olika modeller för att förklara dessa drag, vilket vi skriver om i vår på Personlighet i arbete (kapitel 6). En av dessa modeller är ”the general Dark factor of personality”, D-faktorn, till vilken alla mörka personlighetsdrag kan härledas som tex pyskopati och narcissism. Precis som inom den kognitiva delen av forskningen föreslås här en generell (g) faktor som gemensamt kan förklara en mängd olika mörka sidor hos en person. D-faktorn föreslås representera en gemensam kärna som ligger till grund för samtliga mörka egenskaper och därmed illvilliga beteenden: till exempel mobbning, fusk, hot, förolämpningar, utnyttjande, trakasserier, förödmjukelser, sårande, lögner, manipulation, stöld, hot om våld, och så vidare.
Definitionen av D bygger på att beteenden är kopplade till två olika typer av måluppfyllelse, dels att maximera den egna nyttan: ”Jag gör vad som helst för att få det jag vill”, dels att orsaka andra en förlust i nytta för andra: ”Jag är villig att själv drabbas av negativa konsekvenser för att någon annan, som jag tycker förtjänar det, ska straffas.” Detta ramas in av att beteendena rättfärdigas av illvilliga övertygelser: ”Jag förtjänar helt enkelt mer än andra.” Personer med hög nivå av D motiveras alltså inte av att öka andras nytta, till exempel hjälpa andra i nöd, om inte de själva också drar nytta av det. De får heller inte egen nytta från eller genom andras nytta, till exempel att vara glad för någon annans framgånga.
När D-faktorn definieras i termer av FFM:s faktorer är det särskilt en låg nivå av sympatiskhet (eng Agreeableness, A) som är framträdande, om man vänder på skalan betyder det hög nivå av Antagonism, en faktor som används delvis i psykiatriska diagnoser. Att vara känslomässigt distanserad, skeptisk och misstänksam mot andra och deras intentioner, sakna empati och ödmjukhet, att tänka på sig själv i första hand och att vara manipulativ för att maximera den egna nyttan är alltså utmärkande karaktärsdrag för D-faktorn, men kan också indikera låg nivå av Sympatiskhet.
I en nyligen publicerad artikel menar forskarna (Leigha et al, 2022) att D faktorn inte är något nytt, det är helt enkelt låg nivå av Sympatiskhet, med andra ord hög nivå av Antagonism. Detta är inget nytt inom den psykologiska forskningen, det kallas för ”the Jangle fallacy”, vilket betyder ett felaktigt antagande om att två identiska eller nästan identiska psykologiska begrepp är olika eftersom de är benämns på olika sätt (i detta fall D faktorn och Sympatiskhet, A).
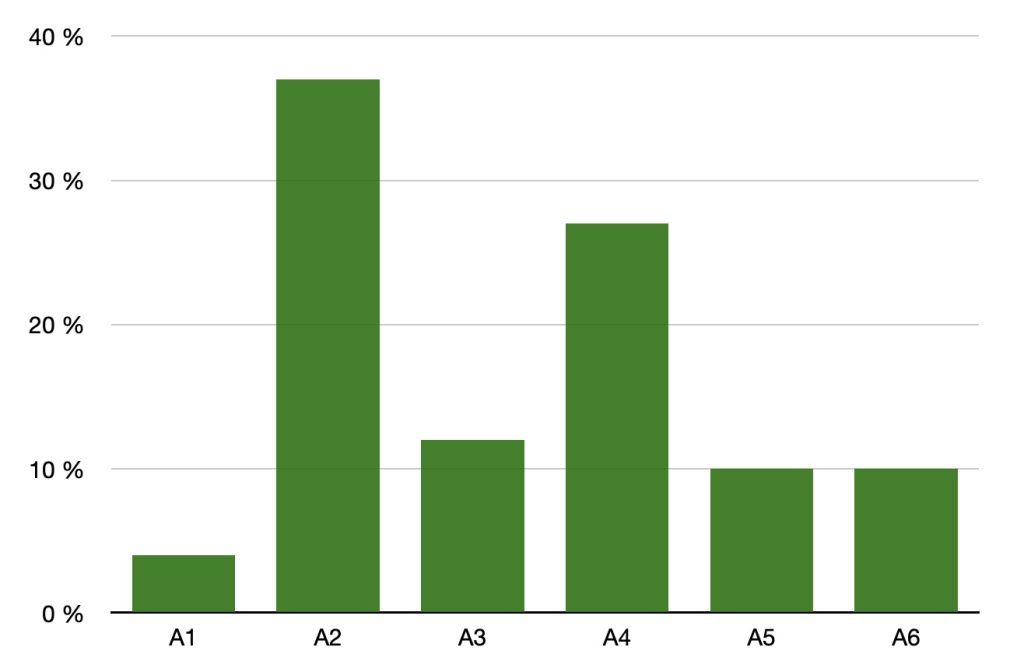
Och det är precis detta som forskarna testar i sin studie, om låg nivå av Sympatiskhet är samma sak som hög nivå av D. Resultatet pekar på att mycket tyder på detta (mer om detta senare). Sambandet mellan de två olika psykologiska begreppen är högt (R=.70), och när jag jag räknar om resultatet från studien. Och när jag sedan fördelar sambandet på de olika facetterna får jag detta resultat.
Jag beräknade sambandet mellan A1-A6 på data från sammanlagt 4 700 testningar av Personality150 (Assessment Engine) samtidigt som korrelationerna mellan A1-A6 togs från refererade studie (Leigha et al, 2022, table 4). Den sammanfattade korrelationsmatrisen användes som input i en relativ regressionsanalys som tar hänsyn till varje facetts unika bidrag till D-faktorn, när alla andra ingående facetter hålls konstanta. Den förklarade variansen uppskattades i steg 1 till ca 50%. All beräkningar genomfördes i (package YHAT) programmeringsspråket R. YHAT fördelar sedan variationen för varje unik facett uttryckt i %. Den förklarade variansen uppskattades i steg 1 till ca 50%.
De två facetter som har högst negativa samband inom Sympatiskhet är A2 (Rättframhet) och A4 (Följsamhet). Låg nivå på A2 innebär att personen har en väl utvecklad förmåga att kunna anpassa sitt sätt att kommunicera med andra för att uppnå de mål personen vill nå. Personer med låg nivå tillämpar ofta denna förmåga och anser att det är en viktig och önskvärd kompetens att manipulera för att få sin vilja fram. Detta innebär att personen är benägen och skicklig på att använda smicker, list och att tänja på sanningen i syfte att nå dit man vill. Personen använder även smicker och lögner, för att göra interaktionen med andra smidigare och på detta sätt få som hen vill.
Låg nivå på A4 innebär att personen har ytterst svårt att vara följsam, mycket skarp i kommunikationen och stark i sitt sätt att argumentera för sina åsikter och ställningstaganden. Håller fast vid sina åsikter, ändrar sig nästan aldrig trots att motargument är övertygande, och personen är tydlig med sin ilska och frustration när hen känner missnöje. Personen står fast vid sina åsikter och hävdar sin rätt gentemot andra utan att tveka, samt tycker mer om tävling och konkurrens och betraktar kompromisser och konsensus som ett nederlag (Sjöberg, Sjöberg, Henrysson Eidvall, 2021). Som sagts ovan, dessa personer motiveras inte av att öka andras nytta, till exempel hjälpa andra i nöd, om inte de själva också drar nytta av det, att vara glad för någon annans framgångar händer aldrig.
Rent kvalitativt är det inte riktigt samma nivå som D faktorn, dvs att beteenden är kopplade så tydligt som i D faktorn, dvs både maximera den egna nyttan och samtidigt orsaka andra en förlust. Även om en låg nivå på Sympatiskhet kanske är ett måste om personen ska komma högt i D faktorn. Min ståndpunkt är att även om det finns ett högt samband mellan A och D, kommer vi inte åt D med de instrument vi idag har och använder i arbetslivet. Låga nivåer på A betyder inte nödvändigtvis att vi på ett korrekt sätt mäter D faktorn, eftersom de typer av frågor som mäter D faktorn inte går att ställa i tex urvalssituationer. Låga nivåer av A2 och A4 kommmer inte så lågt helt enkelt. Nedan är några påståenden som mäter D faktorn.
Payback needs to be quick and nasty.
When I get annoyed, tormenting people makes me feel better.
Det handlar således om extrema nivåer, nivåer som traditionellt inte låter sig bedömas med de metoder och verktyg som finns tillgängliga i dag för användning i arbetslivet. Detta gäller alla slags verktyg: intervjuer, personlighetstest och så vidare. Majoriteten av dessa verktyg är utvecklade för att mäta och skilja mellan individer som är inom normalspannet på de aktuella personlighetsdragen, med en viss variation förstås. De är inte utvecklade för att bedöma eller kunna skilja mellan de mer extrema nivåerna. För att komma åt dessa nivåer krävs det att verktyget redan från operationaliseringen (dvs hur vi mäter det) av konstrukten fokuserar på dessa extrema nivåer, det vill säga redan när verktyget utvecklas. Och dessutom är det etiskt tveksamt om vi bör ställa dessa typer av frågor i en urvalssituation.
Implikationer för praktiker
A och D har mycket gemensamt, men som praktiker ska man inte utgå ifrån att vi fullt ut fångar drag som psykopati, sadism etc med vår vanliga metoder. Bra instrument kan dock fånga extrema nivåer av normal personligheten, som mycket väl kan ställa till skada både skada och nytta för både anställda och arbetsgivare. Är D en Jangle fallacy? Det går idag inte att svara på helt säkert, men min tolkning är att det handlar om på vilken nivå man mäter Sympatiskhet på, normala nivåer av både A och D har beröringspunkter, men ytterligheten, dvs ytterst extrema nivåer av D är något annat än låg grad av A. Alla som är inblandade i bedömningstjänster i arbetslivet bör därför verkligen överväga lämpligheten i att använda denna typ av verktyg, vara noga med att utvärdera kvaliteten i verktygen och vara mycket försiktiga när resultatet används för urvalsbeslut, karriärrådgivning eller för att beskriva individer.
Leigha Rose1, Chelsea E. Sleep , Donald R. Lynam , and Joshua D. Miller (2022). Welcome to the Jangle: Comparing the Empirical Profiles of the “Dark” Factor and Antagonism. ASSESSMENTS. 1–18.
År 2009 utvecklade jag tillsammans med Hunter Mabon ett test; Matrigma. Matrigma byggde på principen matriser, först föreslaget av Charles Spearman som som en god indikator på generell intelligens, förkortat g. Det mest kända matristestet är Ravens Matriser (Raven var student till Spearman). Matrigma och Ravens Matriser hävdas ibland av både akademiker och praktiker att mäta g. Men läser man Spearman noga menade han aldrig att g kan mätas med en typ av problemlösningsfrågor (item), istället var hans utgångspunkt att en närmast oändlig variation av uppgifter i ett test är kapabla att mäta g, eftersom den generella faktorn finns i alla typer av problemlösning. Olyckligtvis hör jag ofta från konsulter och användare av psykologiska test att matriser är ett test som mäter g, men trots att jag och Hunter Mabon skrev att det inte var så i manualen till Matrigma, verkar marknadskrafter förenklat argumentet, nämligen att g kan mätas med ett test, eller en typ av problemlösningsuppgift. Matriser har sin fördel i att det är ett icke-verbalt test, men det väger inte upp nackdelarna att begränsa intelligens till ett test. Nedan kommer jag föreslå ett betydligt bättre sätt att mäta g på i urvalssammanhang, samtidigt som fördelen med Matriser bibehålls.
Först ska jag presentera vad en matris är för något (se nedan exempel).
Ett matristest börjar med enklare uppgifter och sedan blir uppgifterna svårare och svårare. Spearmans teoretiska utgångspunkter var att g-faktorn inte är relaterad till en specifik problemlösning. Spearman benämner detta som ”indifferences of the indicator” – item som tex innehåller verbal, spatial och numerisk information mäter alla g-faktorn. Detta visar sig i att om vi faktoranalyserar verbala, spatiala och numeriska item framkommer det att de item (oberoende av typ) som bäst fångar g-faktorn är de som utmanar förmågan till att se dolda samband, fylla i luckor där information saknas, se relationer mellan objekt, hitta beröringspunkter mellan figurer som skiljer sig åt – det vill säga typer av problemlösning som Spearman benämner ”education of relations and correlates”. Det viktiga är principen att se relationer mellan objekt, oberoende om det är verbala, spatiala eller numeriska item. Faktum är att ju fler typer av problemlösning som handlar om detta, desto bättre mått är det på g. På forskningsspråk benämns detta som konstruktrelevans. Om det är endast en typ av problemlösningsuppgift så benämns mätningen vara underepresentera konstruktet. I klarspråk, matriser är inte enskilt, ett tillräckligt bra mått på g.
Test som består av matriser har funnits på den kommersiella marknaden i över 100 år och det finns idag många väletablerade och välkända så kallade matristest. På senare tid har dock kritik framkommit som pekar på att flera grundläggande antaganden har glömts bort, missförståtts eller åsidosatts när man konstruerat nya, vidareutvecklat befintliga och/eller marknadsfört befintliga matristest (Raven, 2021). En del kritik handlar om själva konstruktionen av uppgifterna ett annat exempel är att det har blivit mer regel än ett undantag att marknadsföra matristest som ”det är bästa sättet att mäta generell problemlösningsförmåga”. Detta påstående kommer att särskådas nedan.
En studie som definitivt slår hål på påståendet att Matriser skulle vara den gyllene vägen att mäta g är en artikel som är skriven av Gilles E. Gignac och publicerad 2015 i tidskriften Intelligens, och titeln är;
Raven’s is not a pure measure of general intelligence: Implications for g factor theory and the brief measurement of g
Data i studien hämtades från sammanlagt tre stora databaser som finns tillgängliga för forskare där personer har fått genomföra en stor mängd olika intelligenstest (16-42 deltest av olika karaktär per individ). När alla dessa test analyserades visade det sig att Matriser EJ stod ut som den bästa indikatorn på g, det var snarare så att Matriser var ”medelbra” i jämförelser med särkilt numeriska och verbala test. I den data som var insamlad i Sverige var det Talserier som visades ha högst samband med g.
Slutsatsen är; för att mäta g finns det oändliga antal sätt att konstruera test. Ett bra mått på g är ett test som tar hänsyn till så många typer av problemlösning som möjligt, därför bör ett matristest kompletteras med deltest som mäter verbala, numeriska och även spatiala förmågor.
Assessment Engine – marknadens vassaste mått på problemlösningsförmåga och personlighet?
På Assessment Engine strävar vi alltid efter att bli bättre och att leverera effektiva processer som följer den senaste forskningen på området. Ett led i det arbetet är att vässa vårt mått på generell problemlösningsförmåga, som är en viktig komponent i de flesta bedömningsprocesser som görs i samband med urval. Vi följer alltid den senaste forskningen och reagerar alltid när nya resultat presenteras. Därför har vi inte bara utvecklat ytterligare ett matris test, vi har följt Spearmans och Ravens grundintentioner när vi utvecklat vårt nya matris test, Logiska Matriser, och kan säga att det är just nu vassaste matristestet på marknaden som ska användas för rekrytering och urval. Men vi nöjer inte med ett test som mäter g utan vårt nya matristest, Logiska Matriser, kombineras med, våra redan utvecklade test, Logiska Talserier (numeriskt test) och Logiska Instruktioner (ett kombinerat verbalt och spatialt test). Även om vi inte kan säga att vi täcker hela konstruktet generell intelligens vågar vi säga att det är det bästa på marknaden som på ett snabbt och korrekt sätt fångar vår generella problemlösningsförmåga. Från 1 oktober finns vårt nya mått på intelligens för alla våra användare på Assessment Engine (utan att man behöver betala för ytterligare ett test). Vill du prova på Assessment Engine, en modern licensfri fri tjänst som bygger på ISO10667 (bedömningstjänster i arbetslivet), så bjuder vi på upp till 5 testningar beroende på om du kombinerar vårt nya mått på g med vårt ”Big Five” personlighetstest (P150) och intresse motivationstest (AIM). Alla våra bedömningstjänster bygger på den absolut senaste forskningen. Vill du veta mer om hur vi bedömer personlighet rekommenderas vår bok, Personlighet i arbete.
Referens
Gignac, Gilles E.( 2015). Raven’s is not a pure measure of general intelligence: Implications for g factor theory and the brief measurement of g. Intelligence, Volume 52, Pages 71-79.
En fråga som jag ofta får är om personligheten förändras över tid. Vi svarar på den frågan i vår bok Personlighet i arbete. Men forskningen går hela tiden framåt så nedan kan du läsa om det absolut senaste forskningen om personlighet i förändring. Tack till Stefan Söderfjäll som tipsade om artikeln).
Ett grundläggande antagande inom den s k traitpsykologin, är att personlighetsdrag är stabila över tid. Detta antagande har fått kritik och går ofta även stick i stäv med vad enskilda individer vittnar om i sina enskilda betraktelser. Ofta hör jag personer prata om sin egen utveckling och att olika livshändelser påverkat deras personlighet, dvs jag som individ ”är inte är samma person som jag var förut innan detta hände mig”. Modern traitbaserad personlighetspsykologi grundar sig istället på antagandet att personlighetsdrag är relativt stabila över tid men att det finns en viss dynamik både inom och mellan personlighetsdrag som kan bidra till förändring över tid. Nu har en intressant studie (se referens nedan) försökt svara på hur och på vilket sätt personlighetsdrag är stabila eller instabila över lång tid sett ur ett individuellt perspektiv.
Det vi skriver om i vår bok är hur forskningen traditionellt undersökt två typer av stabilitet. En typ är absolut stabilitet. Absolut stabilitet talar om hur stabilt ett personlighetsdrag är över tid om personen jämförs med en större grupp, tex om medelvärdet sjunker eller höjs för individen över tid. En annan typ av stabilitet fokuserar på hur stabil rangordningen är mellan människor med en viss nivå av en personlighetsegenskap. Vi konstaterar i vår bok Personlighet i arbete att medelvärdet och rangordningen förvisso kan förändras i riktade beteendeförändringar, men forskningen tyder på att personlighetsdrag är stabila både i medelvärde och rangordning, även om vissa drag som till exempel extraversion sjunker något på ålderns höst (särskilt energin går ned med högre ålder).
Även om dessa typer av förändring är intressanta så missar dessa analyser en viktig aspekt och det är att se till hela personlighetsprofilen i en och samma analys. Detta kallas på forskningsspråk personcentrerad personlighet, mer tekniskt för ipsativ personlighet.
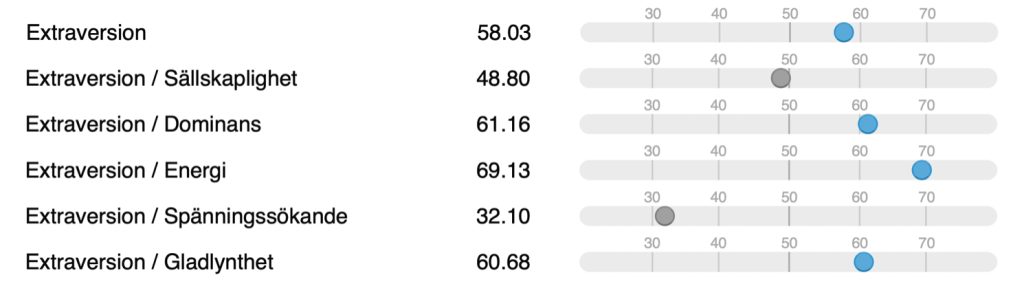
Nedan kan ni se en personlighetsprofil av en individ vid ett tillfälle avseende personlighetsfaktorn Extraversion, vi kan kalla hen Anders (Anders heter egentligen något annat). Vi ser att Anders karaktärsdrag (vi kan säga att han är 58 år), i faktorn Extraversion, när han så sakteliga är påväg till pension, ligger nästan 1 standardavvikelse (58.08 T-poäng) högre än genomsnittet i den grupp individer som han jämförs med och som består av personer i arbete i Sverige.
Anders nivåer på faktorn Extraversion och dess facetter
Detta är en sk normativ absolut jämförelse: Anders nivå jämförs med en annan grupp individer. Om vi hade haft Anders T-värde på Extraversion när han var 20 år (med samma normgrupp och samma instrument för att mäta Extraversion) så skulle vi kunna jämföra Anders absoluta stabilitet över 38 år. Hade vi dessutom för hela gruppen haft en korrelation mellan två tillfällen på Extraversion så skulle vi kunna säga något om både hela gruppens relativa stabilitet, och även Anders relativa stabilitet, dvs om man jämförs med övriga i gruppen hur mycket mer eller mindre extravert har Anders blivit. Vi kan även undersöka den relativa stabiliteten i de s k facetter som ingår i faktorn Extraversion (Sällskaplighet, Dominans, Energi, Spänningssökande och Gladlynthet). Inom forskningen är det ofta normativ och relativ jämförelse som undersöks när man pratar om stabilitet eller förändring av personlighetsdrag.
Ett personcentrerat synsätt på stabilitet och förändring tar istället utgångspunkt i den sammantagna profilen, dvs att Anders karaktärsdrag är hög Energi och lågt Spänningssökande, förhöjd Dominans och Gladlynthet och genomsnittlig nivå på Sällskaplighet. När denna analys genomförs struntar man i andras värden på Extraversion utan ser enbart på den individuella profilen över tid, men andra ord en ipsativ jämförelse, även kallad inom-individ variation.
Den studie som nu publicerats undersöker hela profilen i femfaktormodellen och undersöker stabiliteten för sammanlagt 21 616 personer där den längsta tiden mellan mätningarna av personlighetsprofiler är 34 år!
Innan jag redovisar resultatet bör frågeställningen klargöras och hypoteserna som testas tydliggöras. Det finns, som alltid inom forskningen, olika synsätt där olika forskningsgrupper hävdar ”sin hypotes”. Om vi först skiljer på de mest extrema hypoteserna. Den första hypotesen är att personligheten endast kan förklaras av situationen, dvs miljön som personen befinner sig i. Det individen upplever i form av tidig uppväxt, partnerskap och senare arbete har en direkt påverkan på personligheten vid en bestämd tidpunkt. Då situationer ofta (men inte alltid) är mer eller mindre slumpmässiga skulle detta betyda att personlighet inte är stabil, alla dessa situationer ger upphov till att vem som helst kan uppvisa alla typer av kombinationer av personlighetsdrag över tid, beroende på upplevelser. Omsatt i exemplet Anders skulle detta betyda att det han har upplevt fram till 58 års ålder resulterat i den ovan redovisad profilen av Extraversion. En förklaring till den låga nivån av Spänningssökande skulle på så sätt vara resultatet av en händelse (slumpmässig eller inte) där Anders i tidigt liv sökte spänning och råkade ut för en olycka, vilket i sin tur sänkte hans nivå av spänningssökande.
Den andra extrema hypotesen är att allt beror på genetik och arv, att vi fullt ut ärver vår personlighet av våra biologiska föräldrar. Genetikens påverkan är ofta kontroversiell och ses som deterministisk och förutbestämd, trots att även det genetiska anlaget bjuder på både elasticitet och variation.
Det är bra att känna till att när man inom personlighetsforskningen talar om vikten av genetik och miljö menar man vanligtvis skillnaden mellan individer. Det vill säga, hur stor del av variationen mellan individer när det gäller till exempel personlighetsegenskapen extraversion som kan förklaras av eller härledas till genetiska faktorer. Man avser inte att ett visst antal procent av varje enskild individs nivå av extraversion kan härledas till genetiska faktorer, det är således inte ett perspektiv inom individen utan mellan individer. Vi vet inte heller hur mycket varje person får från sin mamma eller pappa, i genomsnitt är det 50% men i extrema fall så kan en individ få 90% från den ena föräldern och 10% av den andra. Forskning visar att genetiska faktorer förklarar omkring 40 procent av den variation som finns mellan individer när det gäller personlighet. Arv borde även bidra till att den individuella personlighetsprofilen är stabil över tid, dvs den ipsativa jämförelsen uppvisar stabilitet.
Det är få forskare idag som intar någon av dessa extrema positioner (100% arv alternativt miljö) och eftersom de genetiska faktorerna endast står för cirka 40% av variationen mellan individer så är förmodligen en kompromiss mellan arv och miljö en mer rimlig förklaring. Trots att det finns starka bevis för att personligheten beror på både arv och miljö kan jag höra från akademiska kollegor att det är väldigt svårt att acceptera att hela 40% skulle bero på arv.
Ett tredje perspektiv är att personligheten blir stabilare och stabilare över tid, situationer som inträffar i livet antas här inte vara slumpmässiga. Individen antas först ha en viss genetisk uppsättning som bestämmer nivån på t ex Extraversion. På grund av den medfödda nivån söker sig sedan individen till vissa situationer som bekräftar behovet av Extraversion. För Anders del så skulle det betyda att Spänningssökande kunde ligga på högre eller lägre nivåer i yngre ålder, men över tid har nivån av spänningssökande stabiliserats runt 30 T-poäng beroende på medvetna val han gjort, dvs ”play safe” (Anders har aldrig gillat gå på gröna Lund för att åka fritt fall).
Ett fjärde perspektiv är att det finns en skillnad i förändringsbenägenhet mellan individer, dvs att vissa individer har lättare eller större benägenhet att förändra sin personlighet i jämförelse med andra. Detta skulle betyda om man jämför en större grupp över tid skulle en del förändra sig och andra skulle uppvisa stabilitet, oberoende av vilken situationer eller miljöer personerna befinner sig i. Detta perspektiv kan antingen ha en direkt påverkan på personligheten, oberoende av arv och miljö men kan också samvariera med arv och miljö för att påverka en individs personlighetsprofil.
Alla dessa perspektiv kan naturligtvis tillsammans förklara en individs förändring och stabilitet i personlighet över tid. Vad kommer då forskarna fram till i sin studie?
På ett övergripande plan kan man dra slutsatsen att personlighetsprofilerna är stabila över tid: de allra flesta ”behåller” sin personlighetsprofil genom sin livscykel. Men, det finns också individer som kontinuerligt förändrar sin personlighet. Detta förklaras av en individuell differens som INTE kan förklaras av slumpmässiga situationer.
Den genetiska faktorn och sökandet av situationer som bekräftar personligheten har betydligt större effekt i jämförelse med livshändelser. Ett intressant fynd är att de som tidigt förändrar sin personlighet tenderar att fortsätta med det genom livet, medan de som är stabila från början följer den trenden livet ut.
En slutsats som dras är att dessa resultat pekar på att situationer har en högst begränsad effekt på en individs personlighet över tid. Detta säger å andra sidan inte att livshändelser inte kan påverka personligheten på kort tid, men det tyder på att individen sedan oftast går tillbaka till det karaktärsdrag som man hade innan händelsen.
När det gäller ålder så finns det en skillnad mellan yngre och äldre. Efter man nått åldern 30 verkar de flesta personer uppvisa en stabil personlighetsprofil. Tidigare normativa jämförelser visar att Målmedvetenhet och Sympatiskhet höjs med åldern medan Neuroticism sjunker ju äldre man blir. Dock är det relativt små skillnader. Omsatt i Anders resultat kan han under vissa omständigheter i livet visat på en betydligt lägre nivå i Extraversion men över tid kommer han återvända till 58.08 poäng.
Den övergripande slutsatsen som forskarna drar är att vår personlighet är stabil över tid men att vissa individer tidigt kan visa på större förändringsbenägenhet än andra. Denna förändringsbenägenhet består sedan senare i livet. Forskarna föreslår att det är genetiska faktorer och det faktum att vi söker bekräftelse av vår personlighet som står för stabiliteten.
Jag föreslår därför att man bör lägga till en faktor i FemFaktorModellen: grad förändringsbenägenhet/stabilitet.
Vad kan vi då säga om Anders resultat? Inte mycket mer än att det än att hans nivå på Extraversion ser ut såhär idag, Det hade varit intressant och se hans resultat vid 5, 10, 15, 20, 25, 30 etc års ålder, då hade vi vetat mer om han har förändrat sin personlighet genom livet.
Vad får denna forskning för praktiska implikationer?
När det kommer till att använda personlighetstest i arbetslivet betyder det att resultat från personlighetstest för vissa personer kan vara färskvara. Dessa individer är dock få, de allra flesta har en personlighet som är stabil även under längre tidsperioder. Relevansen i att använda personlighetstest är dock oförändrad. Men att slentrianmässigt, eller strategiskt, ”återanvända” resultat från personlighetstest i rekryteringssammanhang, dvs spara ett resultat för att använda till återkommande urvalsbeslut är inte att rekommendera. Detta gäller särskilt för yngre kandidater där personligheten inte stabiliserats.
Om det finns en individuell skillnad i förändring så kan det bli missvisande resultat, särskilt om resultat återanvänds efter en längre tid. I urvalssammanhang är det viktigt att matcha personlighetsprofilen med det tilltänkta arbetet vid ett tillfälle. Nu blir det än viktigare att göra en seriös arbetsanalys av vilken profil som behövs på arbetet vid ett tillfälle, därför har vi på Assessment Engine utvecklat en metod för detta där man på ett enkelt sätt matchar femfaktormodellen mellan individen och arbetet (ska inte tolkas som en kompetensmodell). Hör av er om ni vill veta mer.
Om personlighetstest används i utvecklingssammanhang är det viktigt, baserat på ovan att undersöka individens stabilitet i personlighetsprofilen. För att veta om individen är mottaglig för förändring bör man mäta personligheten vid minst tvår tillfällen, helst fler. Assessment Engine har utvecklat en metod för att undersöka även detta, hör av er om ni är intresserade.
Jag finns på info@psychometrics.se
Referens
Wright, A. J., & Jackson, J. J. (2022). Are some people more consistent? Examining the stability and underlying processes of personality profile consistency. Journal of Personality and Social Psychology. Advance online publication. https://doi.org/10.1037/pspp0000429
Med psykobabbel avses ”Användning av psykologiska termer och i synnerhet av dagens modeord inom psykologin på ett sätt som bara delvis eller inte alls stämmer med ordens vetenskapliga innebörd”. Sedan mer än 20 år har jag arbetat med att anpassa och utveckla psykologiska test som idag används inom klinisk psykologi (utredning av kognitiva svårigheter hos barn), skolpsykologi (tex läs- och skrivdiagnostik, utredning av dyslexi) och arbetspsykologi (test som används för urval och vägledning). Under dessa år har jag stött på ett antal ”buzzwords” inom dessa områden, här kommer jag dock fokusera på begrepp som används inom arbetspsykologisk testning, dvs psykometribabbel inom arbetslivets psykologi.
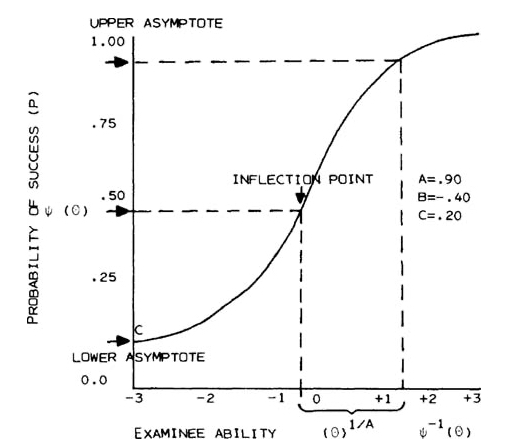
Som alla ser här är detta en tre parameters IRT modell
Artificiell intelligens (AI)
Artificiell intelligens (AI) eller maskinintelligens är förmågan hos datorprogram och robotar att efterlikna människors och andra djurs naturliga intelligens, främst kognitiva funktioner såsom förmågan att lära sig saker av tidigare erfarenheter, förstå naturligt språk, lösa problem, planera en sekvens av handlingar och att generalisera. AI är förmodligen ett av psykometribabbel som används mest osorterat idag. Det kan i stort sätt betyda vad som helst. När man skrapar på ytan hos vissa leverantörer av test kan det vara att summera en skala.
Maskininlärning
Maskininlärning (engelska: machine learning) är ett område inom AI, och därmed inom datavetenskapen. Det handlar om metoder för att med data ”träna” datorer att upptäcka och ”lära” sig regler för att lösa en uppgift, utan att datorerna har programmerats med regler för just den uppgiften. Detta är inget nytt! På ett teoretiskt plan uppfanns detta för många år sedan, men datakraften att räkna på detta sätt saknades. Idag säger flera leverantörer av test att de använder sig av ”machine learning” och det låter ju häftigt! Har själv prövat detta och jämfört med betydligt enklare och mer kostnadseffektiva metoder, och de ger i princip samma resultat. Det finns stora fördelar med maskininlärning på en mängd olika områden, men på testområdet har jag inte funnit stöd för detta, dvs avseende hur väl en testpoäng förutsäger senare arbetsprestation.
Kompetensmodeller
Runt 2005 började olika sk kompetensmodeller dyka upp hos traditionella leverantörer av psykologiska test. Dessförinnan var ett personlighetstest ett test som mäter personlighet (tex Extraversion), och ett kompetenstest ett test som mäter en färdighet som är något annat än personlighet (tex kunskap i programmering). Idag finns det leverantörer som har ett personlighetstest med ofta goda psykometriska egenskaper men kunder förleds tro att testet mäter kompetenser, oftast efter en hemmasnickrad modell som inte är kvalitetssäkrad. Ibland kan till och med användare få sätta ihop sin egen kompetensmodell! Detta är helt klart ett cirkelresonemang. Jag har själv varit med att utveckla ett personlighetstest som idag säljs tillsammans med en mycket diffus kompetensmodell; de psykometriska egenskaperna har blivit godkända av DNV:s granskning enligt EFPA:s kriterier gäller för evidensen och kvalitet som ett personlighetstest. Trots det marknadsförs och användes detta test tillsammans med en helt ovaliderad kompetensmodell, något som inte framgår i marknadsföringen.
Fem Faktor Modellen
FFM är det modell av personlighet som idag har tydligast stöd inom forskningen, många testleverantörer säger sig ha ett FFM test. Vid närmare granskning av hur test utvecklats är det inte många test på den arbetspsykologiska marknaden som uppfyller kravet på att verkligen mäta FFM av den anledningen att det inte framgår hur item (frågorna eller påståendena i testet) konstruerats och hur varje item är länkat till respektive konstrukt som ligger till grund för facetter, aspekter och faktorer. Idag finns det, enligt min mening, tre-fyra test på marknaden som har manualer som beskriver att det var FFM som låg till grund när item (frågor och påståenden) utvecklades och testet med dess skalor konstruerades. Än värre är det när man påstår att intervjuer mäter FFM utan att ha någon som helst dokumentation på vilka grunder den utsagan kan bekräftas. Jag har även hört att vissa påstå att deras kompetensmodeller vilket säkert är ett framgångsrikt marknadsföringsknep som skänker legitimitet.
Att validera ett testresultat
Detta psykometri-babbel hörde jag första gången på 90-talet. Med detta menas att bedömaren (rekryteraren) ska bekräfta att de resultat som kandidaten fått på ett personlighetstest ska verifieras eller förkastas i en intervju med kandidaten. Jag har aldrig sett någon forskning om detta, men risken att den validitet som finns i en testpoäng försvinner då man ställer dessa frågor är betydande. Om man vill ”kontrollera” resultatet bör man istället utveckla intervjufrågor som mäter FFM, dessa intervjuer genomförs sedan helt oberoende av testresultatet. Det mest ”sanna” är sedan medeltalet av dessa två bedömningar. För att detta ska fungera så krävs dock en hel del utvecklingsarbete, något som få är villiga att göra eller har kompetensen till, tyvärr. Sannolikheten är därför stor att man fortsätter att ställa frågor till kandidater som sannolikt ger mer skada än nytta.
Adaptiva test
Adaptiva test bygger på en psykometrisk modell som benämns item respons theory (IRT). Om IRT används på ett korrekt sätt finns en fördel i att man inte behöver administrera exakt samma item till alla personer som ska jämföras. En annan fördel är att du inte behöver ställa lika många frågor i jämförelse med ett traditionellt test, det räcker med att administrera de för den enskilda individen mest relevanta itemen. Ett exempel är ett begåvningstest, där person 1 får 34 uppgifter att besvara medan person 2 endast får 24 uppgifter. Trots detta kan des båda personernas begåvningsnivå jämföras, och till och med utgöra en bättre jämförelse än om båda fått samma antal frågor. På detta sätt kan en leverantör utveckla en ”itembank” med många uppgifter (eller frågor) som sedan kan användas på olika sätt vid testning. Det låter ju fantastiskt, men vad är nackdelen? (I ett poddavsnitt hörde jag enleverantör ondgöra sig över alla andra okunniga psykometriker som inte fattade detta, förutom att hen naturligtvis som hade utvecklat ett adaptivt personlighetstest).
Jo nackdelen (för sådana finns det alltid flera av även om de sällan nämns) är att när man använder IRT så görs en mängd mycket starka antaganden. Dessa antaganden måste alltså uppfyllas för att modellen ska fungera i praktiken. Ett av de viktigaste (men långt ifrån det enda) antagandena är det sk ”lokala oberoendet”. Antagandet om lokalt oberoende innebär att det statistiska sambandet mellan item kan förklaras endast av det latenta begreppet som vi avser att mäta med en skala, tex en frågor i en skala som mäter Extraversion ska förklaras av begreppet Extraversion. Om så inte är fallet, faller IRT modellen modellen totalt. Den är helt enkelt inte längre giltig. Naturligtvis går detta att testa, men det struntar man ofta i när man pratar IRT.
Jag har själv varit med att utveckla test som tillämpar IRT och som testutvecklare anser jag att IRT INTE fungerar i praktiken såsom teorin förutspår. IRT kan fungera med begåvningstest, men jag har tills dags datum inte läst om något personlighetstest som mäter FFM och som uppfyller alla krav som ställs på IRT för att det praktiskt ska fungera. Så säger din testleverantör att de har ett adaptivt personlighetstest så ställ frågan om alla antaganden som finns verkligen uppfylls för den svenska version (eller annan språkversion) som ska användas och låt dem redogöra för det skriftligt. Jag har läst en manual som ser lovande men det är inte ett test som finns på svenska.
Textanalys
Detta begrepp är nära knutet till Maskinlärning, skillnaden är att innan själva analysen omvandlas textmassan till siffror. I ett pilotprojekt jag ledde analyserades öppna enkätsvar med sk ”latent semantisk analys”. Resultatet såg lovande ut men det var ett enormt jobb att göra data analyserbart. Och analysen i sig tog väldigt lång tid. Det finns också lovande resultat inom forskningen där man uppnått minst lika bra resultat av text analys som av att använda numeriska värden för att tex mäta livstillfredställelse (https://psycnet.apa.org/record/2018-31467-001). Tror mycket på detta i framtiden, men hitintills har jag inte sett någon studie som stödjer att textanalys skulle addera någon validitet till ett begåvningstest eller ett personlighetstest som använder traditionell poängsättning.
Användningen av normgrupper
Går det att använda ett test utan normgrupper? Normgruppens funktion är att relatera den individuella testpoängen till en absolut nivå. Låt mig ta ett exempel, om du har testat en person och fått en summapoäng på skalan Sympatiskhet i ett personlighetstest, då vill du veta om denna summa är förhållandevis låg eller hög i jämförelse med andra personer. ”Babblet” här jag har hört är att det finns test på marknaden utan normgrupper? Eller att vi ”inte har normgrupper, vi har stickprov”. Ett annat babbel jag hört är att i den moderna psykometrin inte behövs några normgrupper. Det är sant att man mycket väl kan strunta i normgrupper, om syftet med testningen är att endast rangordna dessa individer längs skalan Sympatiskhet (som exempel) utan att vara intresserad av att säga om en individs summavärde är låg, medel eller högt i förhållande till något. Men så fort du ska uttala dig om en individs absoluta nivå på Sympatiskhet måste ALLTID en normgrupp användas. Det spelar inte någon roll om du använder ”gammal” psykometri från början av 1900-talet eller ”modern psykometri” (som för övrigt inte bör kallas modern psykometri eftersom IRT kan spåras tillbaka till 1940-talet, eller kanske t om tillbaka till 1920-talet när Thurstone lanserade sin absoluta skalning som var inspirerad av psykofysiken).
Detta är bara några exempel på babbel som många gånger har svagt stöd i forskningen. Om du vill att jag ska skriva om mer psykometribabbel så maila mig på info@psychometrics.se
Vår bok Personlighet i arbete som publicerats av Natur och Kultur har fått ett fantastiskt mottagande av personer som är intresserade av att veta mer om sin egen och andras personlighet. När vi började detta projekt hade vi en vision att informera intresserade vad forskningen säger om personlighet. Nu vill vi ta ett steg till och ge kunskap om evidensbaserad bedömning av personlighet i arbete. Vi kommer ge deltagarna den absolut senaste forskningsresultaten avseende Fem Faktor Modellen och extrema personlighetsdrag och även visa hur ni på ett enkelt sätt kan öka tillförlitligheten i personbedömningar i arbetslivet. Välkomna
Utbildning
9 maj 2022 kl 13-16 på Tändstickspalatset i centrala Stockholm samt digitalt via zoom
Kursbok: Sjöberg, S., Sjöberg A., & Henrysson Eidvall S. (2021). Personlighet i arbete. Natur och Kultur.
Pris: 2500 kronor + moms och inklusive kursbok. (Om du redan har boken är kostnaden 2150 kronor + moms – ange i anmälan).
Seminariet anordnas av Sara Henrysson Eidvall, Henrysson Åkerlund AB i samarbete med Sofia och Anders Sjöberg, Assessment Engine
Vill du höra mer om boken klicka här där jag samtalar med Fredrik Hillerborg i programmet Lära från Lärda.
Vill du höra mer om boken klicka här där jag samtalar med Lena Gatenborg Mohns på MPS om hur personligheten sätter ramar för våra styrkor och svagheter på arbetsplatsen?
Vill du läsa om evidensbaserade bedömningar i arbetslivet som följer ISO10667 klicka här
Vill du beställa den nya standarden ISO10667 om bedömningstjänster i arbetslivet, i detta projekt har jag verkat som expert i många år. Om du är uppdragsgivare av personbedömningar klicka här. Är du leverantör av personbedömningar klicka här
Att bedöma personlighet är svårt. Eftersom personlighet alltid är i arbete går det att bedöma med en rad olika metoder. Bedömningen kan vara att se vad du publicerar på Facebook, låta en robot ställa frågor om din personlighet, administrera ett självrapporterande test och/eller låta andra bedöma din personlighet. I mitt förra inlägg redovisade jag var forskningen står idag avseende självrapporterande test. Nedan breddar jag dikussionen och tar även upp observatörsskattning.
Fem Faktor Modellen (FFM) bedöms i de allra flesta fallen med ett självrapporterande test. Men faktum är att FFM inte upptäcktes genom självrapporterande test utan genom observatörsskattningar. Det var redan 1961 som forskarna Ernest Tupes och Raymond Christal formulerade det som vi i dag kallar FFM. I huvudsak grundades detta arbete på omfattande observatörsskattningar inom det amerikanska flygvapnet. Observatörsskattningarna faktoranalyserades och resulterade i en preliminär FFM.
Under senare delen av 1960-talet och under 1970-talet drabbades personlighetsforskningen och synen på individuella skillnader av en mer allmän, stark kritik från olika håll. Det var inte politiskt korrekt att tala om att människor skiljer sig åt, i synnerhet inte om sådana skillnader som till stora delar är ärftliga. Personlighetsforskningen föll mer eller mindre i glömska. Det var inte förrän på 1980-talet, när forskarna Paul T. Costa och Robert R. McCrae genomförde studier om personlighetsutveckling, som arbetet med FFM togs upp igen. Även då med observatörsskattningar. Paul T. Costa och Robert R. McCrae kunde då replikera Ernest Tupes och Raymond Christals fynd, drygt 20 år senare. Tanken bakom en observerad bedömningsmetod av personlighet är att andra uppfattar individens personlighet på ett annat, mer korrekt sätt i jämförelse med individen själv och/eller att betraktaren ser andra saker i jämförelse med individen själv. Så den självrapporterande personligheten bör således kompletteras med observatörskattningar av personlighet, för att ge en mer träffsäker bedömning
Jag har sammanfattat forskningen nedan vad vi idag vet om självrapporterande test och observatörsskattningar baserat på studierna som ni hittar i referenslistan. Jag har även adderat egen insamlad data. För att göra en komplett uppskattning behövs följande.
Samband mellan de ingående faktorerna i FFM (Känslomässig Instabilitet, Extraversion, Öppenhet, Sympatiskhet och Målmedvetenhet.
Samband mellan de ingående faktorerna i FFM och kriteriet arbetsprestation. Data för detta går att hitta i forskningstudier (se referenslistan), förutom sambanden mellan de ingående faktorerna i FFM för kontextualiserade test.
Det opublicerade resultatet som jag använde i mina beräkningar hämtade jag från Assessment Engine Manualen där vi beskriver standardiseringen av vårt nya kontextualiserade personlighetstest Personality30 (Assessment Engine Assessments & Algorithms Technical Info, 2020).
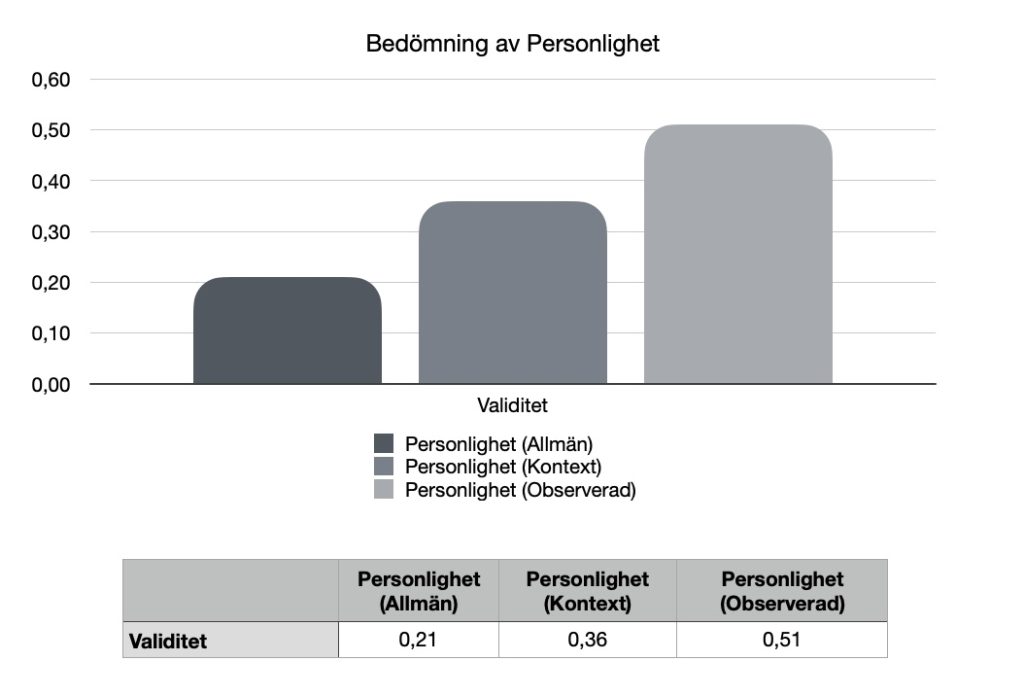
För att beräkna validiteten använde jag programmet R (package yhat). Genom att beräkna en linjär regressionsanalys baserat på ovan redovisad data kan den sammanlagda validiteten (multiple R) uppskattas för tre olika sätt att bedöma personlighet. Allmänna (okontextualiserade) personlighetstest, kontextualiserade personlighetstest och test som baseras på observatörsskattningar.
Not. Observera att estimatet för observerad personlighet antar att det är en person som observerat. Om det är flera personer som observerar så ökar sannolikt validiteten. Mer forskning behövs, särkilt för kontextualiserade test och observatörsskattningar för att de flesta studierna som meta analyserna bygger på har inte undersökt hur dessa metoder fungerar i skarpt läge.
Resultatet i figuren visar validiteten uttryckt i en multipel korrelation för allmänna personlighetstest, kontextualiserade personlighets test och observatörsskattningar. Lägst validitet har allmänna okontextualiserade personlighetstest och högst validitet har observatörsskattningar.
Det är naturligtvis praktiska utmaningar med olika bedömningsmetoder, särskilt med observatörsskattningar. Vi på Assessment Engine tror dock att detta går att lösa, vill ni veta mer om vår nyutvecklade bedömningstjänst ”observerad personlighet” eller testa vårt kontextualiserade personlighetstest, ett av få test som verkligen bygger på hela FFM och utvecklat för arbetslivet, får ni gärna kontakta oss på team@assessmentengine.se.
Vill ni läsa mer om Assessment Engine kan ni klicka här.
Referenser
Assessment Engine. Assessments & Algorithms Technical Info (2020). opublicerat manuscript. Psychometrics Sweden AB.
Connelly, B. S., & Ones, D. S. (2010). An other perspective on personality: Meta-analytic integration of observers’ accuracy and predictive validity. Psychological Bulletin, 136(6), 1092–1122. https://doi.org/10.1037/a0021212
Oh, I.-S., Wang, G., & Mount, M. K. (2011). Validity of observer ratings of the five-factor model of personality traits: A meta-analysis. Journal of Applied Psychology, 96(4), 762–773. https://doi.org/10.1037/a0021832
Park, HyeSoo (Hailey) , Wiernik, Brenton M. , Oh, In-Sue , Gonzalez-Mulé, Erik , Ones, Deniz S. , & Lee, Youngduk. Journal of Applied Psychology, Vol 105(12), 1490-1529
Sackett, P. R., Zhang, C., Berry, C. M., & Lievens, F. (2021, December 30). Revisiting Meta-Analytic Estimates of Validity in Personnel Selection: Addressing Systematic Overcorrection for Restriction of Range. Journal of Applied Psychology. Advance online publication. http://dx.doi.org/10.1037/apl0000994.
Shaffer, J. A., & Postlethwaite, B. E. (2012). A matter of context: A metaanalytic investigation of the relative validity of contextualized and noncontextualized personality measures. Personnel Psychology, 65(3), 445–494. https://doi.org/10.1111/j.1744-6570.2012.01250.x
Sjöberg, S., Sjöberg A., & Henrysson Eidvall, S. (2021). Personlighet i arbete. Förstå drivkrafter bakom och beteenden bakom femfaktormodellen. Natur & Kultur.
Personlighetstest som bedömningsmetod har fått mycket kritik i media under senaste åren. Enligt min mening är det ofta på grund av okunskap från de som kritiserar, sällan behandlas vilken teori personlighetstestet utgår ifrån, om det ska användas som en beskrivning av personen eller om det ska vara underlag för ett urvalsbeslut. Inte heller diskuteras när i en urvalsprocess ett personlighetstest ska administreras till sökande till en tjänst. Nedan kommer en alldeles färsk sammanställning vad forskningen säger om självrapporterande personlighetstest.
I den senaste sammanställningen av forskning kring metoder som kan användas för urvalsbeslut jämförs olika typer självrapporterande personlighetstest. Författarna skiljer på två olika personlighetstest. Allmänna och kontextualiserade test. I allmänna test får personen som bedöms instruktioner att svara på frågorna hur personen tänker känner och handlar i största allmänhet i olika situationer. Kontextualiserade test anger en specifik situation, i detta fall hur personen tänker känner och handlar på arbetet eller i en yrkesroll.
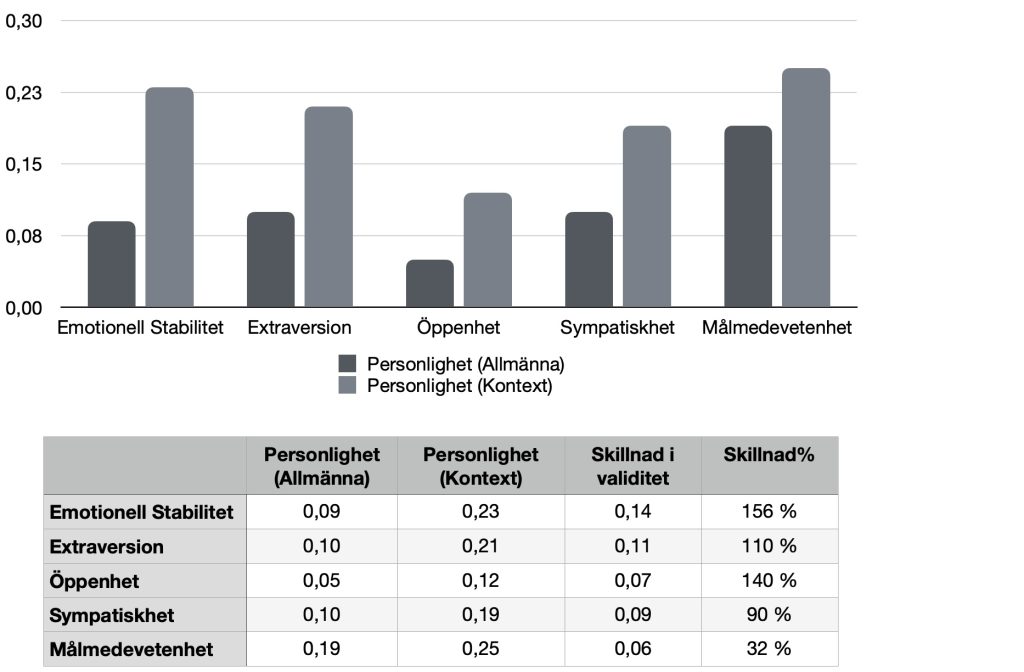
Resultatet presenterades redan 2012 men har nu sammanställts och beräknats om med delvis nya metoder och publicerats i samma artikel som jag bloggade om förra veckan. Nedan ser ni resultatet när en jämförelse genomförs mellan allmänna och kontextualiserade personlighetstest. Resultatet är uppdelat i de fem stora personlighetsdragen, känslomässig stabilitet, extraversion, öppenhet, sympatiskhet och målmedvetenhet.
Figur. Allmänna och Kontextualiserade personlighetstest
Som ni ser är det tydliga resultat, test som i instruktionerna anger att personen ska tänka på en arbetssituationen har betydligt högre validitet i jämförelse med de allmänna personlighetstesten som ej definierar en arbetssituation. Det är särskilt emotionell stabilitet och öppenhet där de största skillnaderna finns. Men även de andra faktorerna visar på en klar förhöjd validitet. Så slutsatsen är tydlig. Använd personlighetstest som är kontextualiserade. Forskarna har en förklaring till detta vilket benämns Frame Of Reference (FOR). Det betyder att frågar du tydligt vilken situation som avses så höjs validiten betydligt.
Vill ni börja använda ett personlighetstest som bygger på vår senaste bok om personlighet i arbete? Ett test som från början utvecklades och validerades i en arbetande population och där instruktioner och frågor handlar om hur personen som testas tänker, känner och handlar i arbetet. Vi kallar det Personality150. Kolla in denna adress www.assessmentengine.se
Sjöberg, S., Sjöberg A., & Henrysson Eidvall, S. (2021). Personlighet i arbete. Förstå drivkrafter och beteenden med femfaktormodellen. Natur & Kultur.
Och det är inte slut här, i nästa blogg gör jag en jämförelse mellan observatörsskattningar och självrapporterade personlighetstest som vi skriver om i vår bok Personlighet i arbete.
Referenser
Sackett, P. R., Zhang, C., Berry, C. M., & Lievens, F. (2021, December 30). Revisiting Meta-Analytic Estimates of Validity in Personnel Selection: Addressing Systematic Overcorrection for Restriction of Range. Journal of Applied Psychology. Advance online publication. http://dx.doi.org/10.1037/apl0000994. Table 4.
Shaffer, J. A., & Postlethwaite, B. E. (2012). A matter of context: A metaanalytic investigation of the relative validity of contextualized and noncontextualized personality measures. Personnel Psychology, 65(3), 445–494. https://doi.org/10.1111/j.1744-6570.2012.01250.x