Nedan förklarar jag skillnaden mellan två mekaniska tillvägagångssätt att kombinera information från ett personlighetstest och ett IQ test, gränsvärde modellen och den kompensatoriska modellen. Även om ett test visar goda psykometriska egenskaper leder detta inte per automatik till att rätt beslut tas, eftersom tomrummet mellan testningen och beslutet lämnar öppet för tolkning och därmed förvrängning av testresultatet.
Nedan förklarar jag skillnaden mellan två mekaniska tillvägagångssätt att kombinera information från ett personlighetstest och ett IQ test, gränsvärde modellen och den kompensatoriska modellen. Även om ett test visar goda psykometriska egenskaper leder detta inte per automatik till att rätt beslut tas, eftersom tomrummet mellan testningen och beslutet lämnar öppet för tolkning och därmed förvrängning av testresultatet.
Att samla information med hjälp av personlighetstest och begåvningstest är naturligtvis inte tillräckligt för att kunna fatta ett urvalsbeslut. Informationen från testen (tex från ett Big Five test och ett IQ test) behöver värderas/tolkas/vägas samman till en sammantagen bedömning som utgör grunden för rangordningen av kandidaterna. Detta gäller oavsett vilket eller vilka (urvals-) verktyg som används för att samla informationen. Detsamma gäller för CV granskning, intervjuer och andra metoder, men i detta exempel tänker jag på testpoäng på ett personlighetstest som resulterar i 5 olika testpoäng och ett IQ test som resulterar i 1 testpoäng, sammanlagt 6 testpoäng som på något sätt ska vägas samman till en testpoäng, denna testpoäng kan sedan vara en del av ett urvalsbeslut. Det är ett vanligt tillvägagångssätt att rekryteraren använder psykologiska test, med dokumenterat god validitet i testpoängen men att urvalsbesluten är invalida på grund av det som sker mellan testpoängen och beslutet, alltså själva sammanvägningen av testpoängen inte är maximal. För att råda bot mot detta kommer jag nedan argumentera att använda en sk kompensatorisk modell istället som vad många använder idag, en modell med olika gränsvärden, sk cut-off värden. Först ger jag ett exempel på cut-off modellen, sedan kommer ett exempel på en kompensatorisk modell.
Gränsvärde
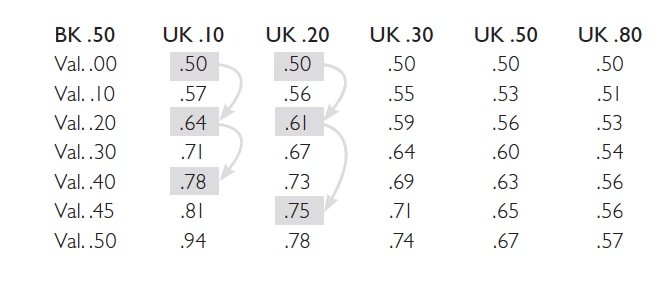
I gränsvärde modellen anges gränsvärden för samtliga testpoäng på våra test. Tänk er att testpoängen kan variera mellan 0 och 10 poäng. Vi benämner faktorerna enligt vår personlighet- och begåvningsmodell (AG, ES, CO, EX, OP, IQ). Rekryteraren måste här bestämma vid vilka värden varje kandidat ska gå vidare. Varje faktor behandlas här separat. Vi kan börja med AG som mäter personens Sociala Stil (eng, Agreeableness, AG) där höga poäng betyder att personen har sympatisk framtoning när hen umgås med andra, medan en låg poäng betyder att personen upplevs lite mer hårdhudad. Här bestämmer vi att på det här jobbet ska en person ha minst mede sympatiska medarbetare, vi sätter gränsvärdet till 5. Sedan går vi vidare till nästa faktor, Emotionells Stabilitet (ES). Här bedömer vi inte att det behövs mer än 3 poäng. Sedan fortsätter vi genom alla faktorer vilket resulterar i följande gränsvärden.
- AG 5
- ES 3
- CO 7
- EX 0
- OP 3
- IQ 5
Att varje faktor behandlas var för sig blir tydligt om vi tänker oss en kandidat som får, AG=4, ES=10, CO=10, EX=5, OP=10, IQ=10. Denna person är en begåvad person som är ytterst målmedveten (några av de viktigaste faktorerna för att förutsäga arbetsprestation), men på grund av en 4:a på AG kommer denna person inte rekommenderas för jobbet.
Fördelen med denna modell är att det ofta är lätt att förklara för chefer som ska ta urvalsbeslut, men den har några väldigt ogynnsamma antaganden som i praktiken sällan uppfylls.
För det första så antas det att alla testpoäng är helt oberoende av varandra, vilket inte uppfylls i praktiken. Även om testpoängen heter olika saker betyder det inte att testpoängen är oberoende varandra, det finns ett samband mellan faktorerna. Tex finns det ett positivt samband mellan målmedvetenhet (eng, Conscientiousness, CO) och AG, vilket vi inte tar hänsyn till i modellen. Med andra ord när vi accepterar resultatet som ett gränsvärde tror vi att vi bara väljer på AG, medan i praktiken tar vi också beslut på CO.
För det andra antar denna modell att vi vet exakt var gränsvärdet ska sättas. Detta är alltid gjort med väldigt mycket subjektivitet för vi vet sällan hur en enskild nivå exakt påverkar ett beteende på arbetsplatsen. Att sätta exakta gränsvärden kan fungera när det gäller fysisk styrka (tex man måste kunna bära en viss tyngd) eller kunskap (baskunskap i programmering), men jag skulle säga aldrig när det gäller personlighet och begåvningstest.
För det tredje, enligt min mening den allvarligaste bristen, tillåter man inte att vissa faktorer kan kompensera varandra. Ett exempel från forskningen är hur målmedvetenhet (CO) och IQ samvarierar för att för att förutsäga lärande. En person med relativt låg IQ kan lära sig lika mycket som en person med relativt högre IQ, men en förutsättning för detta är att personen med lågt IQ ligger högt på CO, målmedvetenhet. I cut-off modellen tillåts inte detta hända, eftersom man behandlar en faktor i taget.
Kompensatoriska modellen
I den kompensatorisk modellen finns det inte för varje enskild testpoäng något gränsvärde. Istället reduceras, i detta exempel, 6 olika testpoäng till en slutpoäng, ibland kallad lämplighetspoäng. Denna lämplighetspoäng jämförs mellan individer och den person som har högst poäng rekommenderas till arbetet givet det du mäter, dvs i detta exempel personlighet och begåvning.
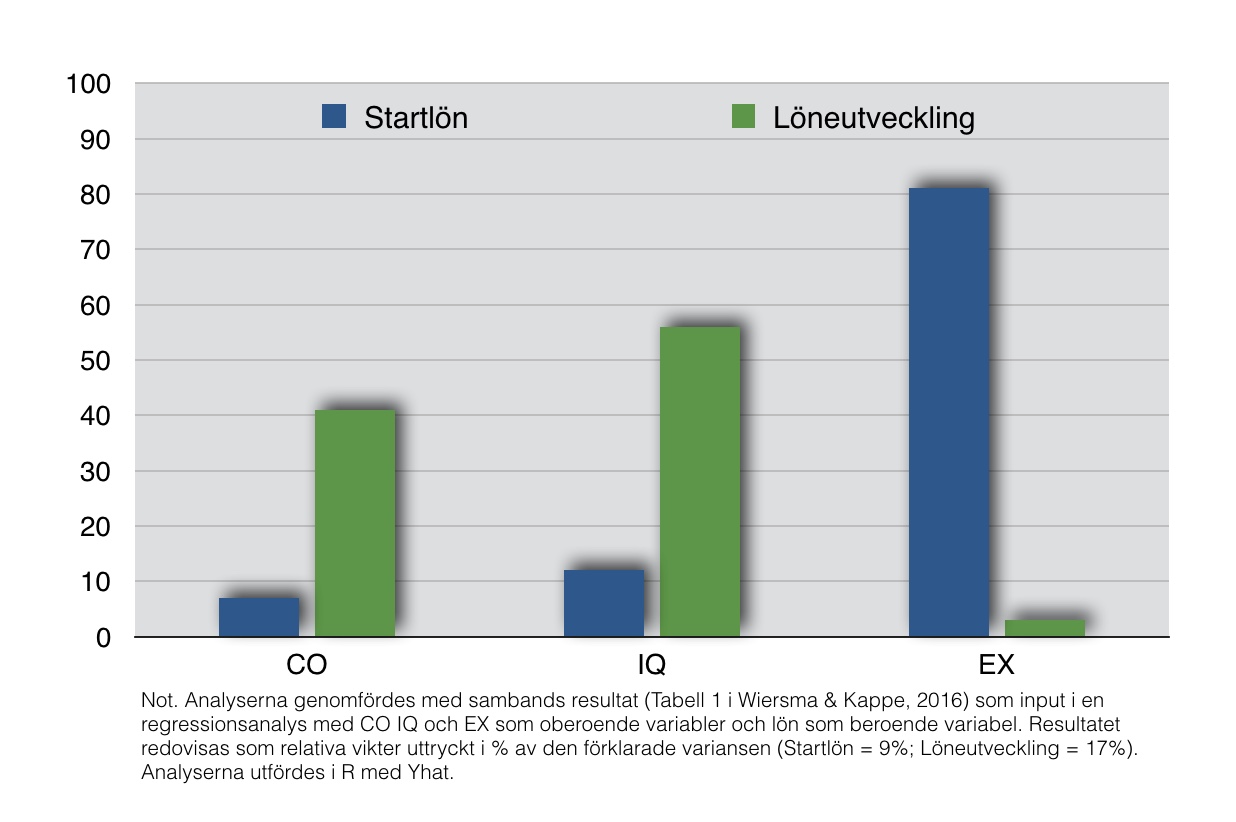
Vikterna för respektive testpoäng är framtagna så att de representerar de optimala vikterna för respektive faktor (prediktor) och varje specifikt kriterie (tex arbetsprestation). Det innebär att vikterna maximalt nyttjar informationen i varje prediktor i förhållande till den empiriska kravprofilen. Detta uppnås bland annat genom att varje beräkning av lämplighetspoäng tar hänsyn till att prediktorerna i viss mån samvarierar (överlappar) med varandra. Graden av samvariation mellan prediktorer estimeras för varje lämplighetspoäng genom empiriska studier och beskrivs för varje enskild slutpoäng. Att vikterna är optimala medför per definition att andra vikter för samma prediktorer inte kan höja den prediktiva validiteten utan enbart sänka den. Med andra ord, avviker vi från de optimala vikterna sänks validiteten i tolkningen av testpoängen.
Sambanden, eller korrelationerna mellan prediktorerna krävs av två skäl: dels för att kunna estimera de optimala vikterna för den aktuella profilen (kriteriet) och därmed maximera träffsäkerheten (validiteten) i det beslutsunderlag som profilerna genererar. Korrelationerna mellan prediktorerna sammanställs i en så kallad korrelationsmatris, denna matris används sedan i en regressionsanalys som estimerar sambanden med kriteriet (det vill säga vikterna). Korrelationerna mellan prediktorerna behövs också för att kunna leverera beslutsunderlag som bygger på en kompensatorisk modell (det vill säga att till exempel låga poäng på en skala CO till viss del kan kompenseras med höga poäng på IQ). Notera att det kompensatoriska förhållningssättet brukar tillskrivas den intuitiva tolkningen – att den implicita tolkningen hanterar och justerar just detta – trots att den i själva verket omöjliggör ett kompensatorisk förhållningssätt eftersom den intuitiva tokningen inte leder till samma viktning för varje individ. Se exemplet nedan när alla faktorer viktas i till en slutlig poäng.
- AG * 1
- ES * 2
- CO * 3
- EX * 1
- OP * 1
- IQ * 6
Genom att multiplicera med varje testpoäng med en siffra (en konstant) så blir varje kandidat bedömd med samma måttstock. En kandidat kan kompensera poäng med andra poäng.
Fördelen med denna modell är:
- ingen enskild faktor sorterar bort individer
- låga poäng på en faktor kan kombineras med höga på en annan faktor
- varje kandidat blir bedömd på samma premisser
Det går även att kombinera gränsvärden med en kompensatorisk modell. Gränsvärden kan används av logistiska skäl, tex när det är låga urvalskvoter, dvs många sökande till få platser. Då kan gränsvärden användas genom att ställa ”låga” krav i början av urvalsprocessen eller i slutet av processen. Gränsvärden kan också användas i slutet av urvalsprocessen när en kompensatorisk modell valt bort de lämpligaste kandidaterna. Detta kommer jag berätta om i kommande inlägg på psychometrics. Vill du läsa mer om hur kompensatoriska modellen fungerar i Evidensbaserat urval ((EBU™), klicka här.
Lästips
Dawes, R. M., & Corrigan, B. (1974). Linear models in decision making. Psychological Bulletin, 81, 95-106.
Dawes, R. M. (1979). The robust beauty of improper linear models in decision making. American Psychologist, 7, 571-582.
Freyd, M. (1926). The statistical viewpoint in vocational selection. Journal of Applied Psychology, 4, 349-356.
Grove, W. M., Zald, D. H., Lebow, B. S., Snitz, B. E., & Nelson, C. (2000). Clinical versus mechanical prediction: A meta-analysis. Psychological Assessment, 1, 19-30.
Kleinmuntz, B. (1990). Why we still use our heads instead of formulas: Toward an integrative approach. Psychological Bulletin, 3, 296-310.
Meehl, P. E. (1954). Clinical versus statistical prediction. A theoretical analysis and a review of evidence. Minneapolis; University of Minnesota Press.
Meehl, P. E. (1986). Causes and effects of my disturbing little book. Journal of Personality Assessment, 50, 370-375.
Newman, D.A., Jacobs, R. R., & Bartram, D. (2007). Choosing the best method for local validity estimation: Relative accuracy of meta-analysis versus a local study versus bayes-analysis. Journal of Applied Psychology. 92, 1394-1413.
Schmidt, F. L., Shaffer. J. A., & Oh, I. S. (2008). Increased accuracy for range restriction corrections: Implications for the role of personality and general mental ability in job and training performance. Personell Psychology, 61, 827-868
Viswesvaran, C., Ones, D. S., & Schmidt, F. L. (1996). Comparative analysis of the reliability of job performance ratings. Journal of Applied Psychology, 81, 557-574.
Viteles, M. S. (1925). The clinical viewpoint in vocational selection. Journal of Applied Psychology, 2, 131-138.