 Psychometrics berör ofta bedömningstjänster som har med urval att göra. Psykologiska tests kvalitetet diskuteras ofta, det krävs att testen är båder reliabla och valida. Det finns granskningsintitutet där oberoende granskare bedömer kvalitetet i både test och urvalsprocess. Enligt min mening har detta både höjt kvaliteteten och statusen på marknaden på psykologiska test inom arbetslivet och på sikt kommer det höja kvaliteten i urvalsprocessen. Men, hur är det med metoder som används för utveckling och förändring? En ny forskningssammanställning (Barends, Janssen, ten Have, & ten Have, 2014) visar att kvaliteten i dessa utvärderingsstudier är under all kritik.
Psychometrics berör ofta bedömningstjänster som har med urval att göra. Psykologiska tests kvalitetet diskuteras ofta, det krävs att testen är båder reliabla och valida. Det finns granskningsintitutet där oberoende granskare bedömer kvalitetet i både test och urvalsprocess. Enligt min mening har detta både höjt kvaliteteten och statusen på marknaden på psykologiska test inom arbetslivet och på sikt kommer det höja kvaliteten i urvalsprocessen. Men, hur är det med metoder som används för utveckling och förändring? En ny forskningssammanställning (Barends, Janssen, ten Have, & ten Have, 2014) visar att kvaliteten i dessa utvärderingsstudier är under all kritik.
Idag finns det ca 4,2 miljoner anställda i Sverige, av dessa är över en halv miljon chefer. Dessa chefer utgör ett enorm marknadspotential för alla yrkesgrupper som arbetar med chefer/ledares utveckling. Det kan vara allt från att man får höra en bergsklättrare prata om ledarskap, till program som pågår under år för att utveckla och förändra chefer till något bättre. Upphandlingar i mångmiljonklassen är inte ovanliga för dessa typ av tjänster från myndigheter och andra offentliga institutioner. Det handlar alltså om förändring av beteende av chefer och medarbetare som sin tur antas påverka organisationers måluppfyllelse. Men vad finns det för typ av evidens att alla dessa insatser verkligen fungerar som det är avsett?
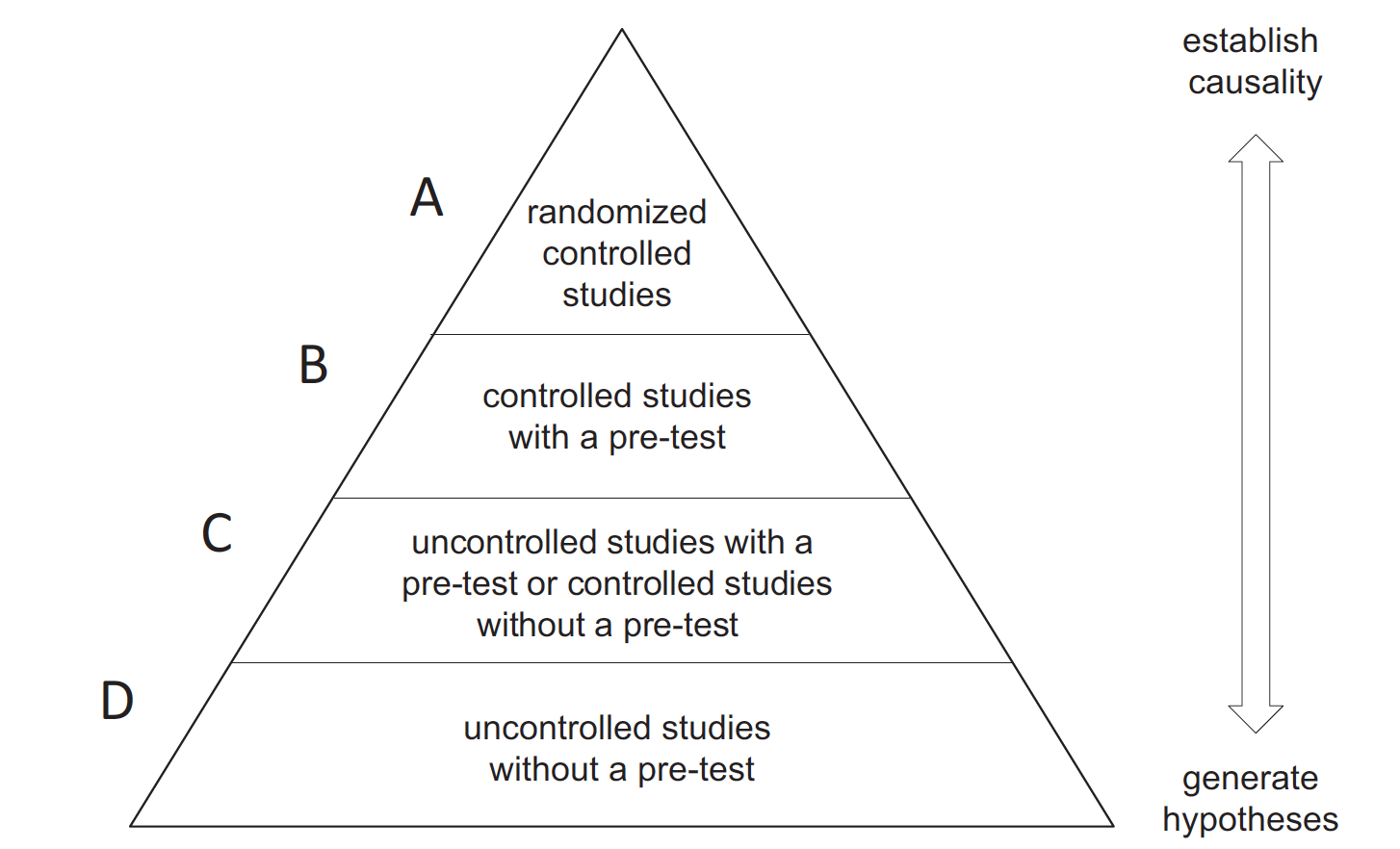
För några år sedan gick jag och en kollega igenom litteraturen avseende ledarskapsförändring, även om resultatet visade på att ledarskap interventioner hade en effekt, så slog det mig när vi gick igenom den samlad forskningen att det var endast ett fåtal studier vars design verkligen kunde prova hypotesen att det var insatsen som påverkade det man ville förändra. Nu har en sammanställning över alla artiklar som undersökt förändringsinsatser publicerats som på något sätt berör ”organizational change management”. Det kan handla om allt från stora strukturella förändringar till teamutveckling och chefsträning. Studien undersöker inte effekten av dessa interventioner utan undersöker vilken typ av forskningsdesign som leder fram till slutsatserna. Forskarna använder sig av en modell där den bäst lämpade designen är en randomiserande experimentell studie med kontroll grupp samt före och efter mätning (A), följt av (B) en studie som har en före-eftermätning men utan kontrollgrupp, (C) kvasistudier som inte är kontrollerande, och (D) helt värdelösa studier utan vare sig det ena eller det andra.
Viktigt att påpeka är att för att dra slutsatser om interventioner fungerar så krävs en kraftfull design av studierna som liknar krav som ställs på läkemedelsprövning (läkemedlet ska bota/lindra en åkomma). Detta skiljer sig från tex studier om urval, där krävs inte samma design eftersom i urval behöver vi inte dra några kausala slutsatser, att intelligenspoäng samvarierar med prestation betyder inte att intelligenspoäng kausalt påverkar prestation, vilket inte är nödvändigt att veta när vi tar urvalsbeslut.
Tillbaka till studien, vad fann du forskarna? Jo, ett ganska nedslående resultat. Av 563 studier som på något sätt undersökt en förändringsinsats så var det endast 10 stycken som nådde nivå A (2%). På nivå B fanns det 54 studier (10%), nivå C, 61 studier (11%). A, B, C kan ändå räknas som bidra till en förståelse vad som påvekar förändring i organisationer men de utgör endast 23% av studierna. De allra flesta studierna kan knappast kallas för forskning, på nivå D fann forskarna 438 studier, hela 77% av studierna uppfyller knappast kravet på att få kallas forskning. Denna design har ingen föremätning, har ingen kontrollgrupp och är utom kontroll för att dra kausala slutsatser.
Slutsatsen så långt är att evidensen att uttala sig om effekter av ”organizational change” givet detta resultat vilar på en yttterst bräcklig vetenskaplig grund. Av intresse är dock de 125 studier som ändå kan kallas forskning. Av intresse är att undersöka vilka effekter som mäts i dessa studier. Av 549 unika mått var dock endast 65 mått objektiva prestationsmått. Resterande utgjordes av upplevelsemått på förändring. Sammantaget ger det svagt stöd att dessa studier kan säga något om hur förändringsinsatser fungerar. Än mer nedslående är att det inte blivit bättre de senaste 30 åren:
”Even more disturbing is the fact that the relative proportion of controlled studies into the effectiveness of interventions and/ or moderators within the field has decreased dramatically over the past 30 years, from more than 30% in the early 1980s to just less than 5% in the past decade” (sid 20)
Med tanke på hur mycket kraft som läggs på förändringsinsatser så bygger slutsatserna på en ytterst svag vetenskaplig grund. Mycket på grund av att de som utför insatserna har varken kunskapen eller de ekonomiska resurserna att utföra dessa utvärderingar. Så länge uppdragsgivarna inte börjar ställa krav på leverentörerna är jag rädd att ingenting kommer förändras. Om man tittar på andra områden ser det bättre ut, på den kliniska sidan av psykologin kräver ”köparna” studier som visar på effekt av tex terapiformer, arbetspsykologin borde snegla på denna sida av psykologin där finns det mycket att lära. Sedan önskar jag att forskningsamhället bidrar med forskningsmedel för att utveckla detta område, eftersom det påverkar så många anställda borde en del av skattemedlen finansiera denna typ av forskning.
Referens
Barends, E., Janssen, B., ten Have, W., & ten Have, S. (2014). Effects of change interventions: What kind of evidence do we really have? The Journal of Applied Behavioral Science, 50, 5-27.










